Guidelines For Creating And Managing A Canonical Record Set
Roman Stepanenko
January 1, 2024

Today’s organizations are looking for any competitive advantage they can get. According to a survey by CompTIA, 75% of companies believe they would be stronger if they could properly harness all the data they collect.
One way to unlock the power of your data stores is by implementing a canonical record set. A canonical set of records is a complete and accurate representation of all your data. It can serve as the “single source of truth” for your organization, and it can be a valuable asset when it comes to making data-driven decisions.
There are many benefits to having a canonical record set, such as improved data quality, reduced storage costs, and easier data management. In order to create and manage a canonical record, there are a few things you need to do.
1. Define the Data Attributes to Include
A canonical record should be a complete and accurate representation of an entity–that is, a person, place, thing, concept, or event with a clear identity. For example, a product, a company, or an order can be an entity.
Each entity has a set of attributes, which are the data elements that describe the entity. For example, an entity such as a product might have attributes such as name, price, and color.
In order to create a canonical record, you must first identify all of the sources of data for that entity. This can be a daunting task, especially for large organizations, but it is a necessary one. You may have teams that manage different parts of the data, or silos of information within different systems.
Once you have identified all of the sources of data, you need to determine which attributes are most important to include in the canonical record. This will vary depending on the entity and the business need.
Canonical customer records, for example, often include the customer’s name, address, contact information, and a unique identifier.
The unique identifier is important because it ensures that the record can be linked to other records in the system, even if the customer’s name or address changes. In the case of customer data, the unique identifier may be a customer number, account number, or Social Security number.
2. Find a Place to Store the Canonical Records
Once you know which data elements need to be included, you will need to determine where the canonical record set will be stored. Ideally, it should live in a central location that can be accessed by all systems that need to use it.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

You have a few options here. The first option is to store the canonical record set in a relational database, such as MySQL, SQL Server, or Oracle. This is a good choice if you are already using one of these databases for other purposes. It allows you to query the data and to easily integrate it with other applications. If you choose this option, you will need to design a schema for the data and then write code to populate the database.
If you do not have a relational database available, or if you want to keep the canonical record set separate from other data, you might choose to store it in a flat file, such as a comma-separated values (CSV) file or a tab-delimited file.
The drawback of storing the canonical record set in a flat file is that it can be more difficult to query the data and generate reports. You will also need to be careful to keep the file updated if any of the data elements change.
3. Cleanse and Deduplicate the Data

Cleansing and deduplication are crucial components of data management. Cleansing means ensuring that each data element is accurate and complete, while de-duplication refers to identifying and merging duplicate records
Both cleansing and deduplication can be tedious, time-consuming, and challenging, especially if you have a large volume of data. However, it is essential to do this in order to create a high-quality canonical record set.
There are a number of ways to cleanse and de-duplicate data, but the most efficient route is to use cleansing and deduplication tools. This is especially true if you’re dealing with large amounts of complex data.
There are a number of different software tools available, so be sure to check carefully which features they offer and whether they will work with your data sources.
4. Create the Canonical Record
Once your data is clean and ready, it’s time to create the canonical record set. The steps involved will depend on how you have decided to store your canonical records.
If you are using a relational database, you will need to design a schema for the data. Take a look at the data elements you plan to include, and decide what data type each element should be. For instance, you might decide to include a customer’s first name, last name, and email address. In this case, the first name and last name would be strings and the email address would be a string that is formatted according to the RFC 822 specification.
Once you have designed the schema, you can start writing code to read in the data from the source system, then use it to populate the database.
If you are using a flat (e.g. CSV) file, you will need to standardize how the data elements are formatted and laid out. If you are including a customer’s first name, last name, and email address, which order will the elements appear in, and how will they be written?
Once you have decided on the format of the flat file, you will need to write code to populate the file. This code will read in the data from the source system and then write it to the file.
5. Keep the Canonical Record Up to Date
Your canonical record set is your definitive source of truth, but much of your data is likely subject to change, and new data is coming in all the time. Keeping your canonical records up to date and reliable will require an organized and consistent approach with well-defined roles and responsibilities.
Depending on how your organization is structured, this may be the responsibility of a central team or individual, or it may be distributed across different departments. Regardless, establish processes and governance around the canonical set to ensure it can be trusted and cement its authority.
There are a few different ways to keep the canonical record set up to date. Automated data collection is the most efficient approach, as it requires the least amount of manual effort. Data can be collected automatically from a variety of sources, including website activity, CRM systems, and social media.
If automated data collection is not possible, you can create a process to enter data manually into the canonical record set. This will obviously be much more time-consuming, and there will likely be more of a delay before changes show up, but it may be necessary if data is not available from other sources.
Once data is entered into the canonical record set, it should be validated to ensure that it is accurate and complete. This can be done manually or through automated means.
The frequency of updates will depend on the nature of the data and the needs of the organization. In some cases, the canonical record set may need to be updated daily or even in real time; in others, it may only need to be updated weekly or monthly.
In Summary

A well-managed canonical record set is an invaluable tool, enabling organizations to make the most of their core data.
By establishing and maintaining a clear and consistent set of rules for what data should be included in the canonical record set, housing it in an accessible and easy-to-maintain system, and defining who is responsible for maintaining it, an organization can turn what was once messy, siloed data into fuel for healthy decision-making.
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up?
RecordLinker uses Machine Learning to normalize records across your data systems!
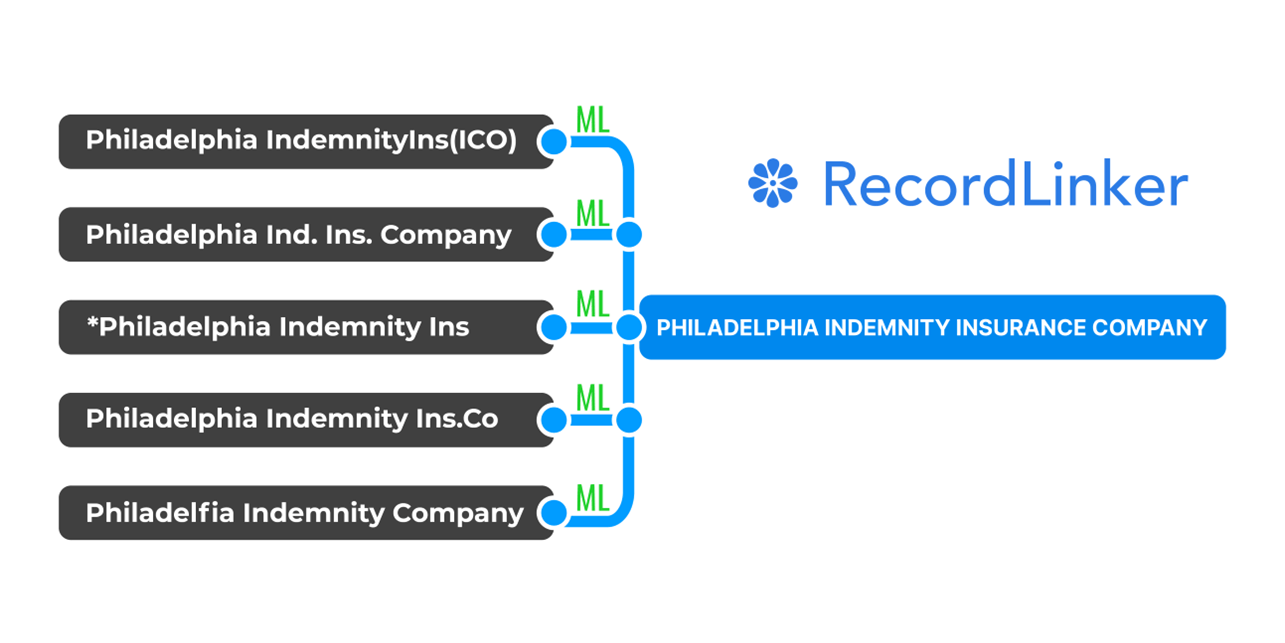
RecordLinker is here to help! Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


