Machine Learning in Entity Resolution: Automating Data Standardization at Scale

Szymon Zak
December 18, 2024

The Core Challenge in Entity Resolution
Real-world data defies simple standardization. A single company might appear as Acme Manufacturing Inc in one system, ACME MFG in another, and Acme Industrial Division in a third – or even within a single system.
Names shift through mergers, rebrands, DBAs, and different data entry practices. Data in your core business systems is neither clean nor well-structured to allow complete automation. Some of records have ‘DNU’ (do not use) or ‘zzz’ prefixes, many of them could be inactive/not for renewal (a case for insurance). Depending on the company, data in the same type of system may differ a lot from a business context standpoint.
That’s why rigid matching rules that work today may easily break tomorrow and fail to address edge cases. The work never ends as systems capture new spelling differences, abbreviations, and data entry patterns. A typical enterprise processes thousands of new records monthly, each introducing potential variations.
Manual Approaches to Data Standardization Fail at Scale
Organizations typically start with manual techniques – spreadsheets for mapping pairs of records with analysts hand-matching things by populating columns. When post-M&A integration comes into play with platform consolidation projects, there are usually some native ways to enable data conversion and mapping records.
However, solutions provided by core system vendors are usually barebones with minimum viable capacity for enabling any data migration and mapping. They lack validation, scalability, and workflows that would help business systems analysts, implementation specialists, and similar roles performing the task. Your analysts still end up manually checking for pairs of records, and only populate mapping spreadsheets or conversion portal dropdowns.
This works for small datasets but fails completely at scale. A large enterprise might easily process 10,000 new records monthly, each potentially containing new name variations. Manual matching creates backlogs, manual versioning, and introduces errors that end up live in your systems.

The Tech Wonder Trap in Automating Data Standardization
Too many times, tech leads and stakeholders feel that they need the ultimate solution for their issue. However, they start from the wrong side – and it sets everything for a massive failure.
They decide to build systems based on deterministic algorithms, exact matching, fuzzy matching, maybe sprinkle it with RegEx. This may alleviate some issues initially, but again, only up to a certain scale and volume. Realistically, you can expect to resolve 30% of matches that way.
Sometimes even more volatile ideas come into play out of frustration. Think about robust spreadsheets or scripts that use libraries of standardized spellings for comparison. What happens again is complete lack of usability for end-users performing matching, failure to adapt to edge cases, and another layer of maintenance issues.
Everyone either gives up at this point or starts experimenting with LLMs. Eventually the focus falls on specialized Machine Learning for entity resolution.
Can Machine Learning solve all your issues? Honestly, no. You can’t hope to automate 100% of data standardization. Trust us, it comes from a team behind an entity resolution company.
But Machine Learning will still help immensely… as long as you address other aspects central to this process. For now, let’s focus on Machine Learning just as a technical solution.
Gen AI and Machine Learning in Entity Resolution
For starters, LLMs may be a good initial relief, but their application is too broad. They are made to cater to a broad range of uses. Their consistency varies, and they are not necessarily a solution you can reliably integrate into your business processes with an interface fit for the task.
Broad generative AI may fail to capture business context and complexities that your analysts base their decisions on. Analysts use them as a relief, but without a proper interface it still ends up being copy-paste work all over the place.
Specialized ML-based entity resolution fundamentally changes your data standardization by learning from historical matches rather than following rigid rules. The system builds pattern recognition capabilities that adapt to new variations while maintaining consistent accuracy. It is trained to do the exact task of matching pairs of reocords.
The core innovation comes from moving beyond simple string matching to understand the contextual patterns that indicate matching entities. When a human expert matches records, they consider multiple factors: similar names, related addresses, industry patterns, known relationships, and temporal proximity. ML models can encode this same contextual understanding at scale.
This contextual learning enables the system to handle complex real-world scenarios:
- A company appears as
IBM Global Servicesin one system andInternational Business Machines Corpin another. The model recognizes these as the same entity based on learned patterns around abbreviations and naming conventions. - An insurance carrier may appear under different names across regions:
Travelers Indemnity Company of ConnecticutversusThe Travelers Companies Inc. The model learns these corporate relationships from training data. - Then there are differences between core systems if you engage in M&A-heavy consolidations. One system e.g. Applied Epic may be using flat structures for entities and one-to-many relationships, another system like AMS360 may be based on parent-child relationships and duplicate child records.
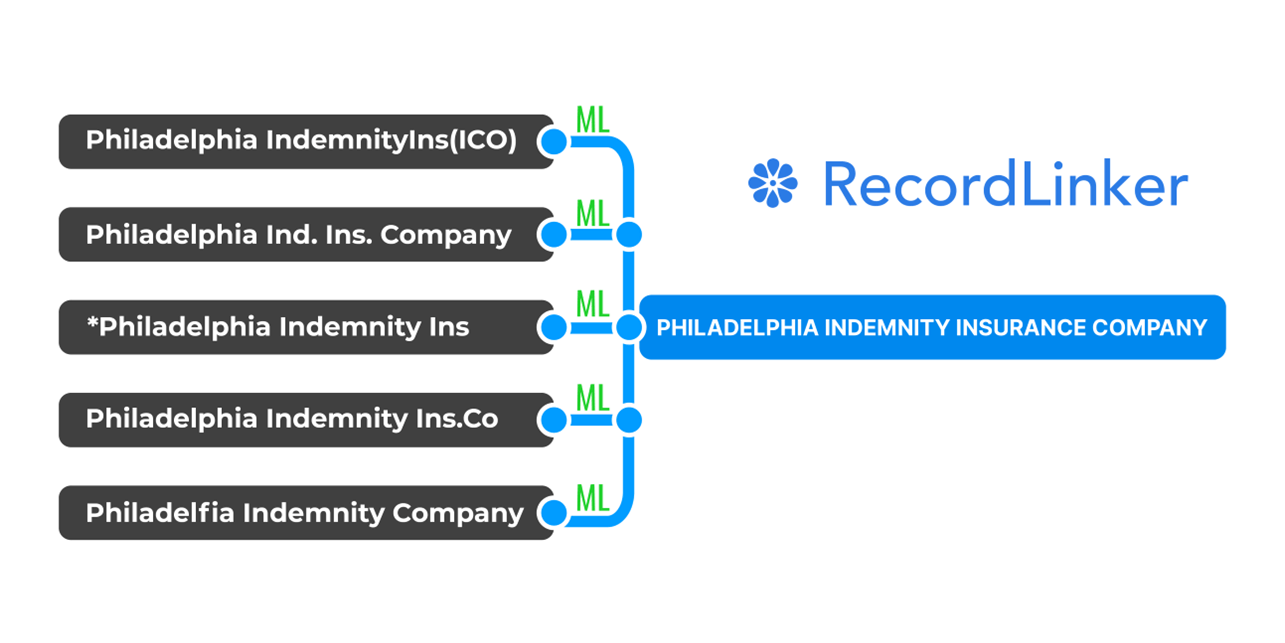
There is something way more important than tech and Machine Learning. By understanding this, you ensure that you don’t end up with gimmicky shelfware.
Solutions and Automation Are The Icing on The Cake
You need to understand one thing. Entity resolution is inherently a part of a business process, it’s a part of the workflow of experts working on data. It sounds noble, but what does it mean?
Your analysts lack a proper environment for their work. Their workflow is riddled with issues, lack of focus, manual versioning, outdated user-hostile interfaces, missing support for collaboration, as well as suboptimal validation that may only prevent obvious mistakes and business rule conflicts.
Typical vendor-native mapping menu looks like an afterthought wrangled into early 2000s UI. Mile-long dropdowns, lack of flexible search, inability to view entities at a glance turn this type of work into utter labor and torment.
Thinking about entity resolution as a tech-first problem is an easy way to miss the needs of your end-users by failing to address huge gaps in usability and workflows.
You Need Your Data Teams for Data Standardization
Here’s a podcast episode about the work of data conversion teams and data admins. While it’s about P&C insurance, it should give you more context why they do amazing and challenging work. What they do is far beyond a simple set of technical tasks. These problems appear throughout many industries in more or less severe form.
The Unseen Data Heroes of Insurance – Listen to Our Guest Episode
Our founder, Roman Stepanenko, shares insights into challenges of data administrators and data conversion teams in insurance.
Discover the gaps in the process, and the reality of manual workflows of insurance's data people. They are some of the most hard-working and unnoticed 'silent teams'.
Data conversion analysts, business systems analysts, implementation specialists, and data admins keep large brokers going after agency acquisitions.
From our experience at RecordLinker, quite a few roles are involved in performing record matching. It’s various sorts of analysts and specialists, sometimes their core responsibilities are not even manual data mapping, but they still get to do it.
When it comes to system consolidation (typical for post-M&A integration), data conversion teams handle the critical work of moving data between systems. They understand source system quirks, data models, destination system requirements, and know how to maintain data integrity through transitions. Their expertise proves vital during system migrations and ongoing data synchronization.
An insurance brokerage’s data admins deal with carrier records daily. They know that Travelers Indemnity and The Travelers Companies Inc represent the same carrier. They understand which divisions write specific coverage types.
Business system analysts translate between technical capabilities, domain knowledge, business context, and operational needs. They understand data challenges, define standardization requirements, and validate the success of automated matching in serving business purposes.
Quality assurance teams validate both technical function and business value. They verify match accuracy, monitor performance, and ensure the solution meets user needs. Their role spans automated testing, manual validation, and user acceptance verification.
Implementation specialists and integration specialists blend configuration expertise with process understanding. They adapt systems to specific organizational requirements. Their role often broadly refers to post-M&A integration rather than just IT integration.
Organizations must invest in these roles for successful data standardization. Machine Learning can semi-automate matching, but human expertise ensures it business needs are addressed, and guides the system’s learning with their deep domain and industry knowledge.
Business systems analysts, implementation specialists, integration specialists, data conversion analysts, and many other admin roles are central to the process.
What should technology aim to do then?
What Happens If You Don’t Enable Your Data Teams
It’s not uncommon for people dealing with entity resolution and data mapping tasks to work overnight. At RecordLinker we build a platform for entity resolution, while it helps our users, we still see their login times. Especially for teams focused on post-M&A data migrations and IT system consolidation work at 2 a.m. and over the weekends can be a thing during a rise in acquisitions.
If you ever wondered about your turnover in data teams, then you should know that this work is very demanding and performed under strict deadlines. People may quit after a particularly demanding project, having faced overwhelming data quality and integrity issues in input data. They may do so for as little as a promise of better work-life balance.
It doesn’t have to be stressful and exhausting like this – but your people need usability, tools, and support for their workflow.
What do we do with a messy business process that burns out people?
What ML and Automation Should Achieve in Entity Resolution
The answer to everything is that you should provide platforms or even ecosystems focused on improvement in work carried out by real people. It’s all about usability, and turning workflows into something doesn’t make people miserable every few weeks.
Your Machine Learning solution (or really any other form of automation) should:
- provide a clean interface, eliminating repeated clickthroughs and the need to find individual records.
- act as a draft environment and system for versioning work.
- recognize its limits through confidence thresholds.
- offer additional validation and approvals.
- provide control by editing linkages, and creating records that may not be present in your destination system.
- use light bi-directional API synchronization with your destination system to reduce implementation complexity and limit work in native tools.
- incorporate third-party industry sources (if available, e.g. AM Best for insurance).
- provide options for project separation, and team collaboration like labels, comments, attachments.
- ML should be able to match independently or enable clustering for larger groups of similar/connected records.
- recognize and honor differences in data models between systems (data relationships, parent-child hierarchies, business rules).
- learn from completed projects to improve accuracy, grow with your organization, and adapt to its changing needs.
- separate data by domains.
Merely matching records is barebones functionality, it won’t work without proper support for the process.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Automating Data Standardization and Entity Resolution Wrapped Up
Entity resolution gains only when we focus on enabling human expertise rather than chasing perfect automation in data standardization. Organizations need platforms that:
- accept the reality of messy business data.
- support natural human workflows.
- integrate smoothly with existing systems.
- ideally, learn and improve through use.
The goal isn’t eliminating human involvement but making it effective and sustainable. Only by recognizing entity resolution as a business process – not just a technical problem – can organizations build solutions that actually work.
Entity resolution is not broken because it needs more automation or tech miracles. It’s an underserved business process with massive gaps in workflows and usability.
The benefits of this approach extend beyond increasing throughput and cutting project timelines. Thinking about this issue human-first and systemically contributes to the happiness of domain experts who often haven’t seen any meaningful improvement over the years of their careers. It keeps the knowledgeable staff in your organization, and you need their expertise to carry out complex processes such as data migrations, platform consolidation, and post-M&A integration.
RecordLinker: User-Friendly Machine Learning in Entity Resolution
Are you acquiring businesses, migrating operations, or consolidating business systems? Do you have a system that suffers from duplication in entities due to persistent data migrations or data entry volume?
We are primarily known for helping some of the top 100 US P&C brokers with their data conversion (mapping data from one acquired system to the destination system post-M&A).
RecordLinker is not an off-shelf product. To really help you, we need to understand your data model, the flavor of your problem, goals, and opportunities for integration to preconfigure our system. Only then we can deliver exceptional value.
Please, feel free to contact us for a demo.
RecordLinker gives an actual useful environment with interface that help people reorganize their work efficiently when compared with native tools and spreadsheet-heavy labor.
This systematizes your business process with our ML added on top for boosting the throughput.
We provide a no-cost trial, allowing your data team to see that meaningful positive change is finally possible.
Suggested Reading about Entity Resolution and Data Standardization
Take a look at our recommended reading list for practical and easy-to-understand resources. We cover topics in-depth to help you gain greater understanding of all things related to entity resolution. Prepare for the right choices about your data management:
- [Guide] Building Your Own Entity Resolution Software
- Normalizing Names of Vendors, Suppliers, and Companies
- Data Normalization: What You Need to Know About Software
- Types of Data Matching Tools: Deterministic vs. Probabilistic Approach
- Centralized MDM and Single Source of Truth Can Disrupt Your Data
- Data Integrity During Ongoing Data Management and Migrations


