Types and Uses of Data Matching Tools
Roman Stepanenko
February 18, 2024

Large enterprises have a lot of data. And with all that data comes the challenge of keeping it organized and accurate – or more specifically, making sure that their data is being leveraged to its full potential.
One key way to do this is through record or data matching, which is the process of connecting data records that correspond to the same canonical (master) entity.
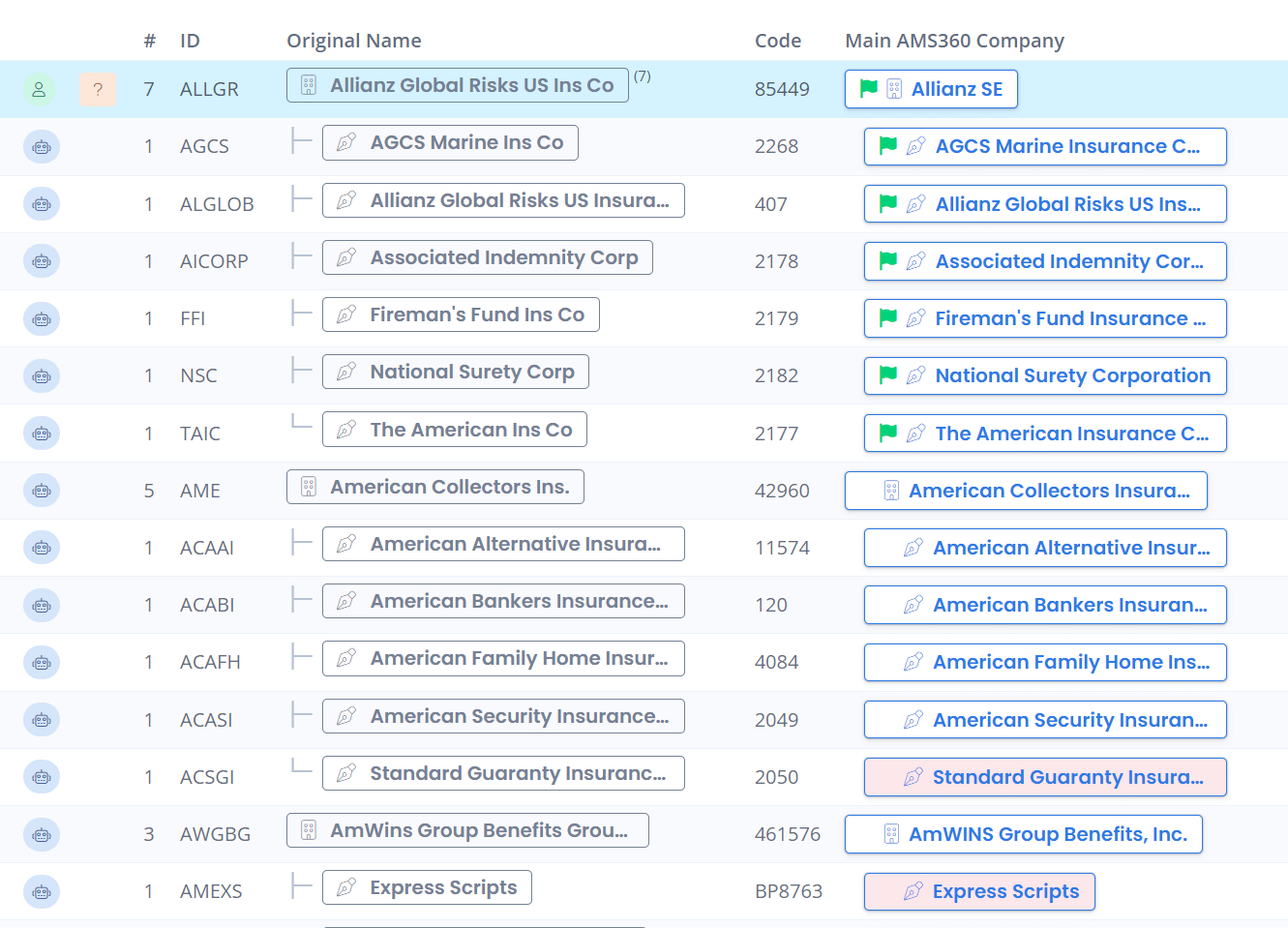
Most enterprise databases, due to their breadth and depth of data, will have some degree of duplicates or inaccuracies (e.g. in a database of locations, “San Francisco” may be written as “SF”, “San Fran”, or “SFO”). Data matching tools help to standardize data and improve its quality by identifying these duplicates and linking them to a single, accurate record.
Naturally, software tools have been developed to automate this process. Below, we’ll take a look at the various types of data matching tools available, how they work, and some use cases for each.
Types of Data Matching Tools
There are two main types of data matching tools: probabilistic and deterministic.
Probabilistic Data Linkage Tools
Probabilistic data linkage tools use statistical methods to determine the likelihood that two records refer to the same entity. They work by comparing different fields in the records and assigning a similarity score for each field; the overall similarity score for the two records is then used to make a probabilistic determination of whether they should be linked.
Today, most probabilistic tools employ machine learning algorithms to provide even more accurate results. Regression and natural language processing techniques are often used to automatically identify and extract important features from records, which are then used in the similarity scoring process.
Advantages
- Probabilistic record matching tools can be used on data of any type, including unstructured data.
- Real world data tends to be unstructured, and often poorly maintained due to manual data entry.
- They are able to handle many spelling/coding variants and exceptions that would not be easy to cover with a predefined rigid rule set or even a robust dictionary.
- They are generally more accurate than their counterpart, deterministic data linkage tools (more on this below).
Disadvantages
- They can be more difficult to configure and tune, since there are more parameters that need to be set.
- They require a good amount of data in order to train the machine learning models used for feature extraction and similarity scoring.
- Some of their results are difficult to interpret; since they are based on probabilistic methods, much of the process occurs behind-the-scenes.
Deterministic Data Matching Tools
Deterministic data matching tools, on the other hand, use rule-based methods to connect records. That is, they compare different fields in the records using a system like RegEx and look for exact matches; if two fields match, then the records are linked.
Since deterministic tools use a predetermined set of rules, they are generally much easier to configure than their probabilistic counterparts. However, this also means that they can be less accurate, since they may miss some relationships that don’t fit the rules.
Deterministic data matching tools are often used in cases where data is highly structured and well-defined; for example, when linking records from two different databases that use the same schema. By contrast, probabilistic data linkage tools are better suited for data that is unstructured or has many different schemas.
Advantages
- They are much easier to configure and tune than probabilistic data linkage tools.
- They can be used on data of any type, including unstructured data.
- You don’t need much data in order to use them, since they don’t require training data for machine learning models.
Disadvantages
- They can be less accurate than probabilistic data matching tools, since they may miss some relationships that don’t fit the rules.
- They are often less flexible than probabilistic data matching tools, since they can only compare fields in a predetermined way.
- Some of their results are difficult to interpret; since they are based on deterministic methods, much of the process occurs behind-the-scenes.
Uses of Data Matching Tools
Record matching tools can be used for a variety of tasks, including:
- Data deduplication – identifying and removing duplicate records from your database as a specific form of data quality assurance.
- Data enrichment – combining your data with other data sources in order to enrich it.
- Data integration – connecting different data sources that use different schemas.
- Fraud detection – identifying records that are likely to be fraudulent, based on their similarity to other records in your database or specific features of known examples.
- Building customer 360 profiles: connecting customer data from different sources (e.g. social media, website interactions, customer service interactions) in order to get a complete view of the customer.
In addition to direct benefits to revenue, there are also longer-term benefits to be gained from using record matching tools.
For example, by linking customer data across different channels, you can develop a deeper understanding of customer behavior. This, in turn, can lead to better targeted marketing campaigns and improved customer retention rates. Perhaps the company is gearing up to sell to a large acquirer. In this case, having accurate and up-to-date data is critical in order to get the best price for the business.
Machine Learning in Data Matching Tools
Probabilitic reocrd linkage tools make use of machine learning trained for specific tasks. ML algorithms are what handles confidence scoring of records. In this case we are dealing with machine learning rather than the current wave of AI tools – so, please, don’t confuse it with ChatGPT-like gimmicks. 😉
Machine learning employed for data matching does its task very well, making it a very reliable way of reducing manual work and improving the quality of your data.
Check these articles from our blog to gain better perspective on how it fits into your data processes:
- How Machine Learning Overcomes Data Linkage Inflexibility
- ML in Master Data Management: How Machine Learning Can Improve Your Data
- How To Build Your Own Entity Resolution System
Data Matching Tools: Powerful Aids to Assist With Data Management
Data matching tools can be extremely helpful for companies dealing with a lot of data. They can be used for a variety of tasks, including data quality assurance, data enrichment, and fraud detection.
RecordLinker uses Machine Learning to normalize records across your data systems!
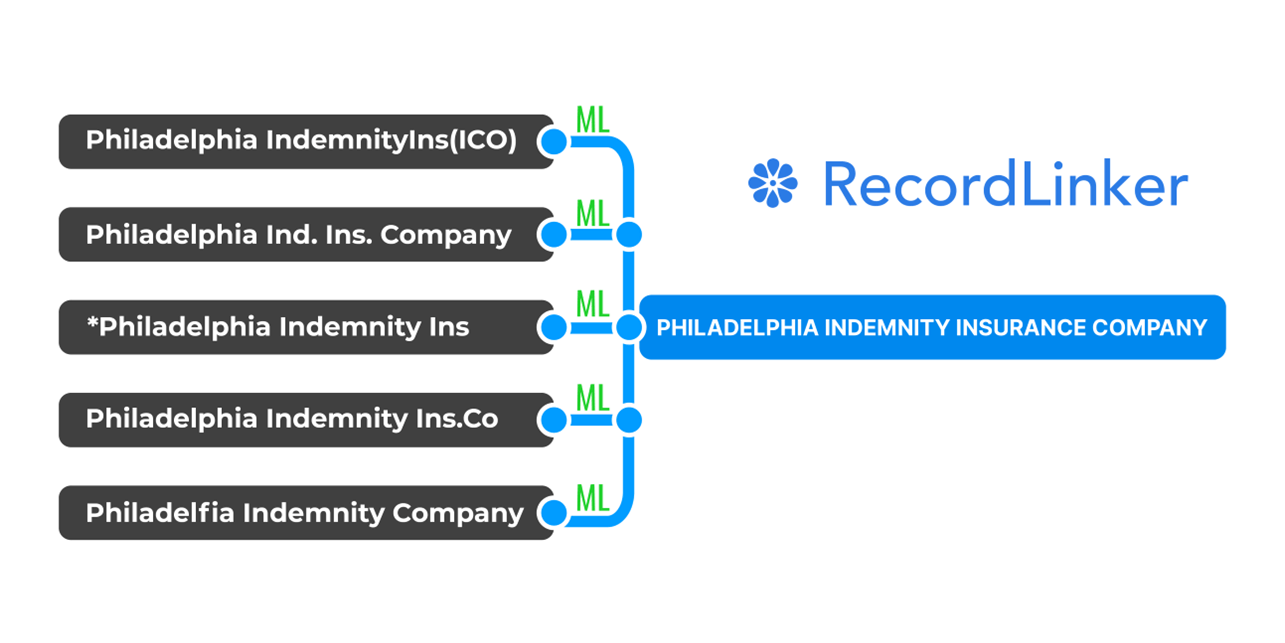
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up? RecordLinker is here to help. Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


