Data Quality Improvement Tips: Machine Learning in MDM
Roman Stepanenko
March 28, 2023

If you’ve ever worked with organizational data, you know it can be messy. Without proper data quality measures in place, the data your organization has can often deteriorate, rendering it unreliable. Master data management is a process and set of tools that help organizations manage their most critical data.
Think of MDM as the central hub where all your important data lives. It’s like having a master blueprint that ensures consistency and accuracy across your organization’s critical data assets. MDM focuses on maintaining a single, reliable source of truth for key data entities like customers, products, and suppliers, ensuring that everyone is working with the same reliable information.
Master data management provides a single, 360-degree view of data that is needed for core business decisions, and ensures that the data is accurate, complete, and consistent across all systems.
There are many ways to approach data quality, but increasingly, organizations are turning to machine learning technology to change their capacity for maintaining data and improving its quality.

Why Is Machine Learning Relevant in MDM?
Machine learning algorithms can sift through mountains of data, identify patterns, and make intelligent decisions. In data management, ML can automate tasks like data cleansing, deduplication, and entity resolution (data linkage), saving time and improving accuracy.
ML techniques, such as classification, clustering, and natural language processing, can be applied to various data management tasks. These algorithms can learn from historical data patterns to progressively identify and correct errors, reconcile inconsistencies, and link related data records with more confidence.
That’s what makes master data management machine learning software so powerful. It can help organizations keep their data accurate, while taking away the brunt of labor these tasks would require when done manually. It frees your talents to focus on more substantive tasks – such as finding new ways to make use of all those data-driven insights.
Data Quality Improvement Strategies and ML
Let’s look through a few ML use cases with examples to show you how to get more out of your data.
1. Customer Data Deduplication
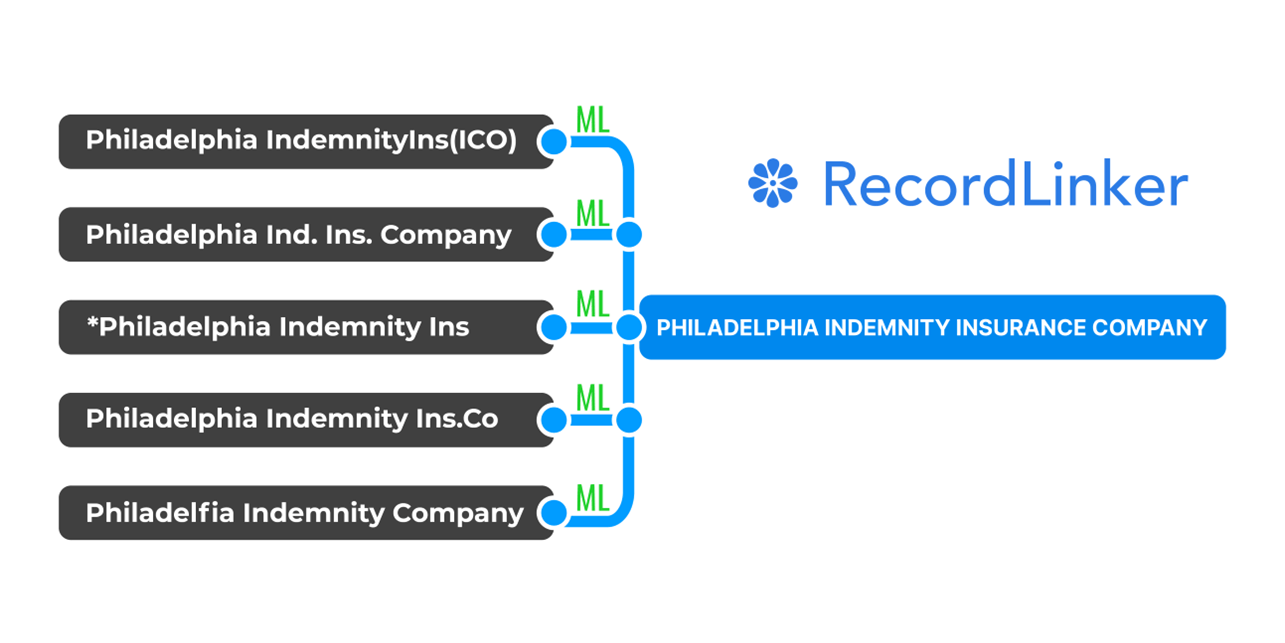
In the retail industry, businesses often encounter duplicate customer records across various touchpoints, such as online purchases, in-store transactions, and loyalty program registrations. Duplicate records can lead to inconsistencies in customer profiles, inaccurate marketing campaigns, and inefficiencies in data management. Machine learning can be applied to perform customer data deduplication, identifying and merging duplicate records to create a single, comprehensive view of each customer.
Let’s take an ML model trained on a dataset of customer information, including names, addresses, contact details, purchase history, and behavioral data. The model learns to recognize patterns and similarities between different customer records and to identify potential duplicates based on common attributes or identifiers.
The ML model is integrated into the retail company’s customer database or CRM system, where it automates the process of customer data deduplication. When new customer data is added to the system or existing data is updated, the model evaluates the similarity between the incoming data and the existing records, using algorithms to determine the likelihood of a duplicate.
When the ML model identifies potential duplicates within the dataset, it generates alerts or notifications for review by data stewards or administrators. These alerts allow the retail company to merge or consolidate duplicate records and resolve any discrepancies or inconsistencies in the customer data.
The quality improvement in customer data translates directly into more accurate measures of average order values, customer lifetime value, and possibly allows retailers to uncover opportunities for cross-selling and creating product bundles.
2. Data Matching and Entity Resolution
A retail bank manages vast amounts of customer data across multiple channels and systems, including account information, transaction history, and customer profiles.
Ensuring the accuracy and completeness of customer data is essential for providing personalized services, detecting fraudulent activities, and complying with regulatory requirements. Machine learning can be applied to perform data matching and entity resolution, consolidating disparate customer records and identifying duplicate or related entities within the dataset.
An ML model is trained on a diverse dataset of customer data, including demographic information, account details, transaction records, and communication preferences. The model learns to recognize patterns and similarities between different customer records and to identify potential matches or relationships based on common attributes, identifiers, and other factors signaling similarity between records.
When new customer data is added to the system or existing data is updated, the model evaluates the similarity between the incoming data and the existing records, using algorithms to determine the likelihood of a match. Matches passing a confidence threshold are left for a review by a data administrator. Ultimately, this results wth complete customer history, better customer service, opportunities for targeted offers, holistic analytics, and tighter fraud investigations.
3. Data Standardization and Normalization
A manufacturing company manages a vast catalog of products with diverse attributes, specifications, and categorizations. Inconsistencies or variations in product data across different systems, databases, and channels can lead to confusion, errors, and inefficiencies. Machine learning can be applied to standardize and normalize product information, ensuring consistency and accuracy across the organization.
This time a machine learning model would be trained on a comprehensive dataset of product information, including attributes such as product names, descriptions, SKUs, categories, and specifications. The ML learns to identify patterns and relationships between different data elements and to recognize common variations or inconsistencies in product data.
The ML model is integrated into the company’s product information management (PIM), ERP system, or a larger data warehouse, where it automates the process of data standardization and normalization. Rather than relying on manual efforts to clean and harmonize product data, the model uses algorithms to identify and resolve discrepancies, aligning product attributes with predefined standards and formats.
When new product data is added to the system or existing data is updated, the ML model automatically applies standardization rules and normalization techniques to ensure consistency and accuracy. For example, it may identify and reconcile variations in product names or characteristics, map product categories to a standardized taxonomy, or validate product specifications against predefined criteria.
Data Standardization in Risk-Sensitive Industries
Data normalization and standardization is very important in industries where following standards is mandatory or necessary to avoid major mishaps.
For the record, a healthcare organization may receive patient data from multiple sources, each using different formats and coding systems for medical conditions and procedures. Machine learning can standardize and normalize this data to ensure consistency, interoperability across systems, and compliance with industry requirements or common standards.
ML models trained on healthcare data can recognize patterns in medical codes and terminology, mapping them to a standardized format such as HL7, SNOMED CT, CPT, and ICD. By automating the process of data standardization, organizations can improve data quality and facilitate seamless data exchange between healthcare providers and systems.
4. Error Correction and Anomaly Detection
A manufacturing company relies on a network of suppliers to provide raw materials and components for production. Inaccuracies or inconsistencies in inventory data or supplier performance can lead to delays, stockouts, and increased costs. Machine learning can be applied to analyze historical data and detect anomalies in inventory levels, procurement, supplier behavior, and transaction patterns.
An ML model trained on historical data of inventory transactions, supplier orders, delivery schedules, and quality assurance metrics could recognize patterns indicative of potential anomalies or deviations from expected norms,
The ML model would be integrated into the company’s inventory management system or a larger data warehouse to continuously analyze incoming data from various sources. This includes ERP systems, warehouse management systems, and supplier databases. Such a solution could operate in batch processing mode, periodically analyzing historical data over specific time intervals (e.g., daily, weekly, or monthly).
Upon detecting anomalies or irregularities, the tool could generate alerts or reports for review by inventory managers or procurement teams.
Based on the insights provided by the ML model, the company can take corrective actions, such as renegotiating supplier contracts, diversifying its supplier base, or implementing more robust inventory management processes to mitigate risks and improve operational efficiency. By leveraging machine learning for inventory management and supplier performance analysis, the company can optimize its supply chain operations, minimize disruptions, and enhance overall business performance.
5. Data Cleansing and Enrichment Automation
In the insurance industry, ensuring the accuracy and completeness of data is vital for effective risk assessment, customer engagement, and claims processing. However, insurers often grapple with incomplete or outdated data from various sources, leading to inefficiencies in their operations. Machine learning offers a powerful solution by automating both data cleansing and enrichment processes, enabling insurers to keep their data sets accurate and enhance them with additional information from diverse sources.
Imagine an ML model trained on a vast dataset encompassing policyholder details, claims history, demographic information, and external data sources such as credit scores and property values. This model learns to identify data gaps and inconsistencies as well as opportunities for enrichment of existing data with valuable insights, such as socio-economic indicators, lifestyle preferences, and risk factors derived from external databases.
Data cleansing involves identifying and correcting errors, inconsistencies, and duplicates within the dataset. Machine learning algorithms can analyze large volumes of data quickly and accurately, flagging incorrect spellings, outdated contact information, and other discrepancies for review. By automating this tedious and error-prone task, insurers can ensure that their data is clean and ready for reliable use.
Integrated into the insurance company’s data infrastructure, machine learning models operate in real-time, continuously cleansing and enriching incoming data streams as new information is received. Whenever inconsistencies or gaps are detected, the algorithms proactively flag them for review or leave enrichment suggestions, ensuring that the dataset remains comprehensive and up-to-date. This proactive approach enables insurers to maintain high-quality data assets and make informed decisions based on accurate and reliable information.
As machine learning algorithms analyze more data over time, they become increasingly adept at identifying and correcting errors. Progressively, they learn to suggest more detailed and accurate information, further optimizing the company’s data assets for maximum value and insight.

Finding Data Relationships and Trends
In addition to improving the accuracy and quality of your data, machine learning can help you understand it.
A major advantage of master data management is that by synthesizing large amounts of master data, organizations can reveal relationships and trends that would otherwise be hidden. Through data categorization, clustering, or predictive models, among other functions, master data management machine learning software can find patterns that humans would miss.
In the world of online retail, understanding what customers want and how they shop is key to success. Machine learning may help e-commerce businesses uncover trends in products, categories, and customer behavior.
Imagine a smart system that learns from past purchases and browsing behavior. It can spot trends like which products are popular together, or suggest complementary items that customers might like based on their shopping history.
Complete customer profiles also open up the way to reliable RFM (recency, frequency, monetary value) analyses, resulting with valuable insights about customer segments.
With a full picture, businesses can take action to improve their offerings and boost sales. They might tweak their product lineup to focus on trending categories, run targeted promotions to encourage customers to buy more, or personalize recommendations to enhance the shopping experience. It’s all about using data to drive smarter decisions and deliver better results.
In addition to finding hidden relationships, machine learning can also be used to identify trends. For example, if an organization has data on customer purchases over time, and product category search data, machine learning can tease out patterns in customer behavior and category opportunities.
You may learn that certain products are becoming more popular, or gain insight into how customer behavior is changing – insights that can be used to sustain a variety of business decisions.
Recap: Data Quality Improvement Strategies
When approached manually or with standard deterministic scrips and rules, data quality improvement becomes a time-consuming and expensive process, often requiring a dedicated team of experts. Machine learning is changing all of that, allowing organizations to manage even highly complex, fast-growing data sets with ease.
Machine learning can be used to improve the quality of data by identifying and correcting errors, filling in missing data, standardizing formats, deduplicating and linking records. It can also predict future trends and help businesses make better decisions.
- Customer data deduplication – with improved data quality and accuracy, companies can enhance customer segmentation and targeting, as well as optimize marketing campaigns and promotions. A single, comprehensive view of each customer enables personalized and relevant interactions as well as improvements in customer satisfaction and loyalty.
- Data matching and entity resolution – improved data quality and integrity enhances customer segmentation and streamlines compliance processes. Accurate and consolidated customer data enables organizations to provide personalized services, detect and prevent fraudulent activities, gain a holistic view of their business, and ensure compliance with regulatory requirements.
- Data standardization and normalization – ML models can recognize patterns in identifiers and industry terminology, mapping these to a standardized format. By automating the process of data standardization, organizations can improve data quality and facilitate seamless data exchange between systems.
- Anomaly detection – when ML supports error and anomaly detection, companies can optimize their supply chain operations, minimize disruptions, and enhance overall business performance.
- Data enrichment – additional information combined with proprietary data lets organizations enjoy more accurate risk assessments, personalized offerings, and targeted marketing strategies.
- Trends analysis – employing ML analytics can help businesses in gaining a competitive edge to drive growth. ML lets stakeholders understand their customers, improve product offerings, and increase sales by making shopping easier and more enjoyable.
Master data management machine learning software can save a lot of time and effort that would otherwise be spent on manual data entry, analysis, and maintenance.
Suggested Reading About Data Quality and Data Management
There is a long way before anyone tackling data quality improvement, and aiming to create foundations for a data-driven organization. Here are some helpful blog posts that explain various concepts and show tactics to give you a solid start:
- Key Components of MDM
- Canonical Data Model in Data Architecture Explained
- Master Data Management Implementation Tips
- Cleaning and Normalizing Your Data For Better Insights
- 10 Customer Master Data Management Best Practices For Success
- Matching Data in Excel: The Wrong Tool for Data Linkage
- [Guide] Developing Your Own Entity Resolution Software
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up?
RecordLinker is here to help. Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.


