Building Your Own Entity Resolution Software for Scalable Data Matching
Roman Stepanenko
May 5, 2023

Data-driven decision-making is critical in today’s business landscape. But even if you collect vast scores of data, it’s only as valuable as your ability to understand and draw insights from it.
Organizations in all industries face the challenge of “messy” data, with records stored across multiple systems.
Why Is Entity Resolution Challenging?
Bringing this data together so that it can be effectively managed and analyzed is easier said than done, since variations in the way records are captured across the sources (e.g. spelling mistakes, abbreviations, word order shifts, capitalization, and even extra spaces) can complicate the process of synthesizing them.
At best, this obstacle costs organizations opportunities to gain meaningful insights. At worst, it leads to high-level mistakes due to leaders’ reliance on fragmented, inaccurate data – which can lead to millions lost.
How do you ensure you have an accurate, up-to-date, and complete view of your most important information? How do you put it together?
Handling Data Matching With Software
RecordLinker was developed as a Machine-Learning-based solution to this problem: entity resolution (aka data matching, record matching etc.).
Our clients use this system to merge data on, for instance, 150 million insurance policy records from thousands of different databases, despite all manner of variations in the spelling of policy coverage and insurance company names (guess how many unique, case-insensitive ways of writing 'Philadelphia Indemnity Insurance Company' we found? 800 variants!)
Given our success, we now help clients across diverse industries get a handle on their disparate data sources.
But what if you wanted to create your own system? Where do you even begin?
In this post, we aim to share what we have learned about in-house entity resolution in order to help you on your journey.
Yes, this is a free, experience-based, transparent, and down to earth guide.
We’ll take you through several use cases of how to build your own entity resolution system and outline best practices for your development team to follow.
The Underlying Problem: Multiple Databases
Let’s say you have several databases or systems that hold important data. Some of these are likely internal but spread across departments. Others may be managed by vendors, third party administrators, or SaaS (Software-as-a-Service) companies. You might be trying to:
- Migrate data from one system to another – happens constantly in insurance with mergers and acquisitions of agencies.
- Fix consistency issues in an information hub, such as a data mart, that draws on copies of records from multiple sources.
- Produce a reliable set of KPIs and a base for reporting by integrating data from more than one database.
In all these scenarios, the challenge you are facing is that records may have different IDs, business codes, and names across systems.
For example, if you’re an insurance company, your General Liability coverage type might be named 'General Liab' in one system and 'Liability-Commercial' in another. Or, misspellings may come into play, such as when 'Ibuprofen' is mistakenly logged as 'Ibeprofen' by your data entry team.
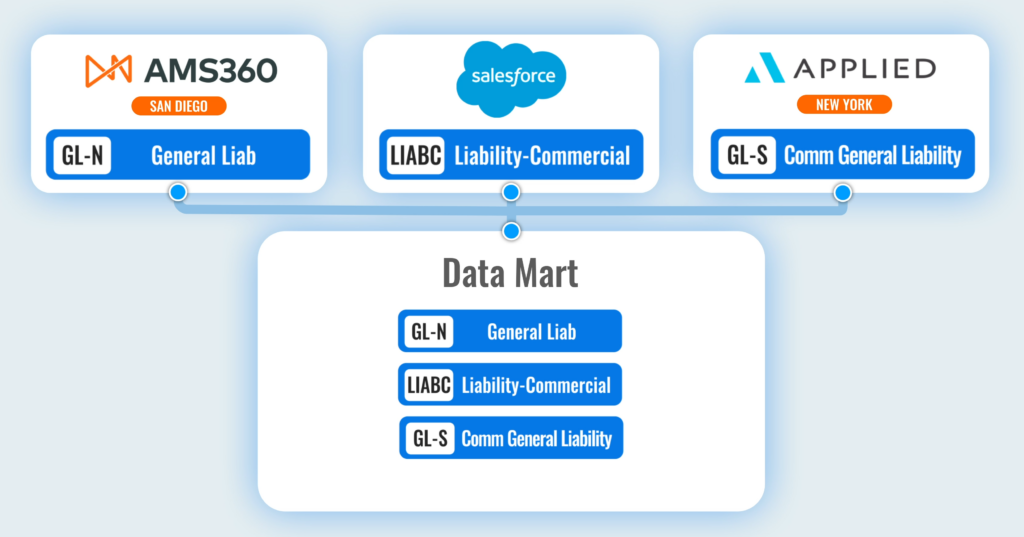
If you tried to match these different records manually, it would be both time-consuming and prone to error. And if you wrote an explicit script to try and automate the process, you would still have to account for the thousands of different ways your data might vary.
Excel, scripts, RegEx – all that relies on deterministic approach to linking data.
It works well with structured data, but real world data is by no means structured, and often prone to changes over time! You would still be left with disparate and erroneous matches – essentially solving a part of the issue while adding work for reviewing and manually fixing the results.
That’s where a flexible data matching software comes in.
The Solution: Canonical Record
The first step in migrating data, or cleaning up a messy data mart, is to identify what the “correct” values should look like. For instance, an insurance company might decide that their General Liability policies should always be referred to in records as 'General Liability' (i.e. not 'General Liab' nor 'Liability-Commercial').
This is usually called a canonical, golden, or master record.
In this post, we will call these “correct values” canonical records.
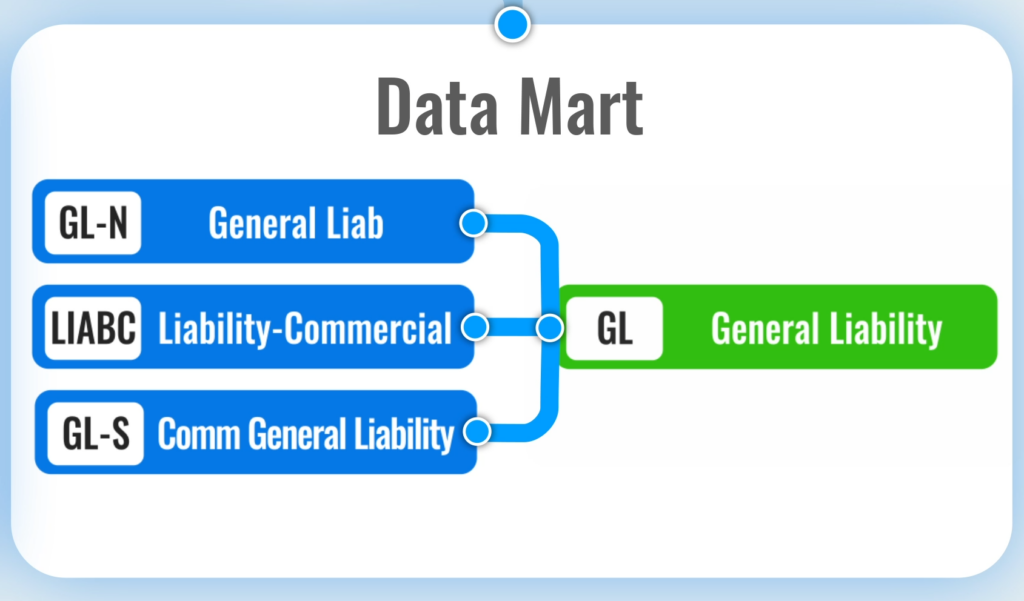
The process of standardizing your existing records so that they match the canonical record is called data normalization (again often synonymously used with entity resolution, data matching etc.)
But before we take you through the process of implementing your own entity resolution system, let’s take a look at a popular, seemingly ready-made solution: Microsoft Excel. It’s surpisingly prevalent in record linkage and data mapping tasks.
Though Excel is a powerful program for many business tasks and offers the advantages of being widely available and user-friendly, it has serious limitations as a entity resolution tool.
Microsoft Excel: The WRONG Tool for Entity Resolution
When organizations decide to get a handle on their data, the first solution they come up with is often this:
‘Let’s build an Excel file where we link input records (things that we need to migrate) to our canonical records (the ‘correct’ values).’
If you really want to dig deeper, we have an entire article explaining why Excel fails miserably at data matching.
The more complex, the more changing, and the lengthier the values get, the worse results it delivers. It’s virtually unmaintainable, and lacks scalability for organizations that need to process hundreds of records daily.
We will just briefly mention the disadvantages of Excel before going into anything that comes with building proprietary entity resolution software!
Such an Excel spreadsheet has two columns: input value and canonical value:
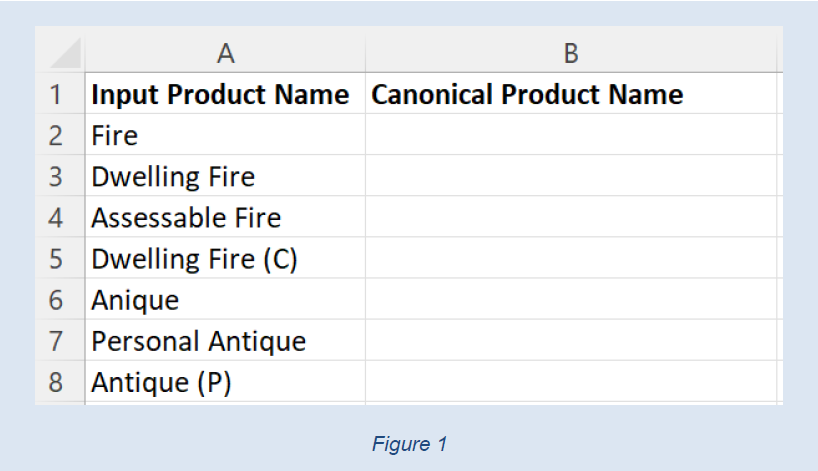
When the canonical values are filled in, the sheet may look something like this:

Unfortunately, using Excel for entity resolution presents two major challenges. At present, solving these issues is extremely tedious and difficult to manage. It’s so bad that using Excel is almost untenable – and here’s why.
Problem 1: Populating Canonical Record Values
Drop-down lists via Data Validation function.
- Someone has to manually create a list of canonical record values and keep it up-to-date.
- The process has to be repeated each time if you want to
add,rename, ormergecertain values. In some business verticals or for some data categories it happens way more often than people would expect. - Dropdowns get cumbersome as your list of canonical records grows. Not a big issue with 10 values, a huge nuisance with 10,000 values to look through.
- This method is unable to handle canonical records that consist of two or more ‘parts’ (i.e. dimensions). You can’t fit a multi-value canonical into a single drop-down list.
VLOOKUP formula
Alternatively, some organizations try to use VLOOKUP to find matches between records in multiple sheets.
- Fails miserably for matching records in spite of different spellings and formats, because it works best with exact match (it needs structured data).
- Approximate match is bad, it often mislinks data categories as simple as names and surnames, which leads to manual work.
- VLOOKUP function stops after finding the first matching value. What if more linkages need to be made to a single canonical record (
company branches,divisions,lines of business,productsetc.)
These Excel methods have a huge potential for errors, by no means are accurate when confronted with somewhat unstructured data, produce an overhead in maintenance work, and lack scalability.
Problem 2: Troubles With Versions
Finally, dealing with new versions of the linkage Excel file can cause a great deal of confusion and error.
- Suppose an employee creates
'Linkages-version1.xlsx, then emails that file to the company’s dev team. - A developer copies the data from that file.
- The initial creator of the file realizes that some records were logged incorrectly, and sends
mappings-v2.xlsxto the dev team. - The developer has to repeat the whole data transfer process, because figuring out what was changed between two versions would take even more time.
Typically, there is a near-constant flow of successive versions of the linkage Excel file, with an increasing risk of miscommunication.
Can you imagine a conversation like this?
‘Wait, I thought we agreed to use version 8 of the Excel file for this release! I emailed that one last Friday, but you’ve used version 7!’
Emailing these files, or storing them in a shared location such as Dropbox, always leads to pain and frustration. Simply don’t do it.
Building Your Own Entity Resolution Software
Implementing your own Machine-Learning-based entity resolution tool may sound challenging, and it certainly requires an initial investment of time and resources.
But the data clarity you can achieve with a robust, reliable system will pay off in dividends over the long-term, in the form of more efficient processes, deeper and more accurate insights, and reduced employee stress.
Development Time Considerations
Prior to starting RecordLinker, we built an in-house solution for a client. It took our team of 5 people around 3 weeks to get the first prototype ready, another 6 months to make it just production-ready, and an additional 6 months of subsequent vital iterations and improvements.
Our work only continues as our end-users keep discovering new use cases, often so complex that we need to implement additional pre-confiugration options or address a specific workflow with its edge cases.
Your flexible in-house entity resolution platform will consist of three major components:
- a database – central repository for the canonical records
- a user interface – the way for users to access and use functionalities.
- Machine Learning capabilities – including retraining.
To create these elements and bring them all together, you will need a development team that knows how to: build web-based UI, work with databases, and implement and train machine learning models.
Guidelines For Developing Entity Resolution Software
We compiled the following guidelines based on our own experience of building an in-house system. Though they are somewhat simplified here, sharing them with your development team will help the project start off on the right foot.
Database Storage
Your database will house your canonical records, input records, and mappings/relationships/connections between them, serving as a single source of truth for your organization’s critical linkage data.
Your database should contain the following elements:
CANONICAL_RECORD table:
ID– (PK i.e. Primary Key) internal ID of the canonical recordVALUE– the canonical name (this is what you will be normalizing to)BUSINESS_CODE– oftentimes, the canonical values include short business abbreviations (codes)
INPUT_RECORD table:
ID– (PK) internal ID of the input recordVALUE– string value of the input record (the value you are trying to normalize)
LINK table:
INPUT_RECORD_ID– an FK (i.e. Primary Key) toINPUT_RECORD.IDCANONICAL_RECORD_ID– nullable, an FK toCANONICAL_RECORD.ID
Side Note – you can merge INPUT_RECORD and LINK into a single table, but over time you might want to have more than one match for the same input record, for example one ‘live’ match and a ‘draft mode’ match possibly leading to another canonical entity. We leave this decision to you.
User Interface (UI) layer
Now, you need to build a UI that allows users to view, navigate, and edit the records in the database. There are many ways to go about building a UI, but whichever method you choose, focus on enabling users to easily perform the following tasks.
Authenticating Users
Authentication ensures that only authorized users can access and edit the canonical records. This is an important element of data security.
Single Sign-On (SSO) is our preferred authentication method, as it allows users to access records without hassle. You may add a secondary layer of authentication like authentication apps or e-mail links if your orgniazation is particularly strict about data security.
Organizing Data Categories for Entity Resolution
Depending on your industry, business specifics, organization of your departments, and separation of duties, you may need to thing how to compartmentalize your solution. Certain types of records will vastly vary with attributes.
By creating data domains, you are also enabling concurrent work. Naturally, Machine Learning will treat and learn from various types of data differently.
Managing Canonical Records
Users should be able to easily create, rename, and delete a canonical record.
Your end-users should also be able to merge several canonical records into one (when this happens, you have to find and update relevant records in the LINK table to point to a new canonical record ID).
The system should keep an audit trail of who renamed, merged, or deleted canonical records.
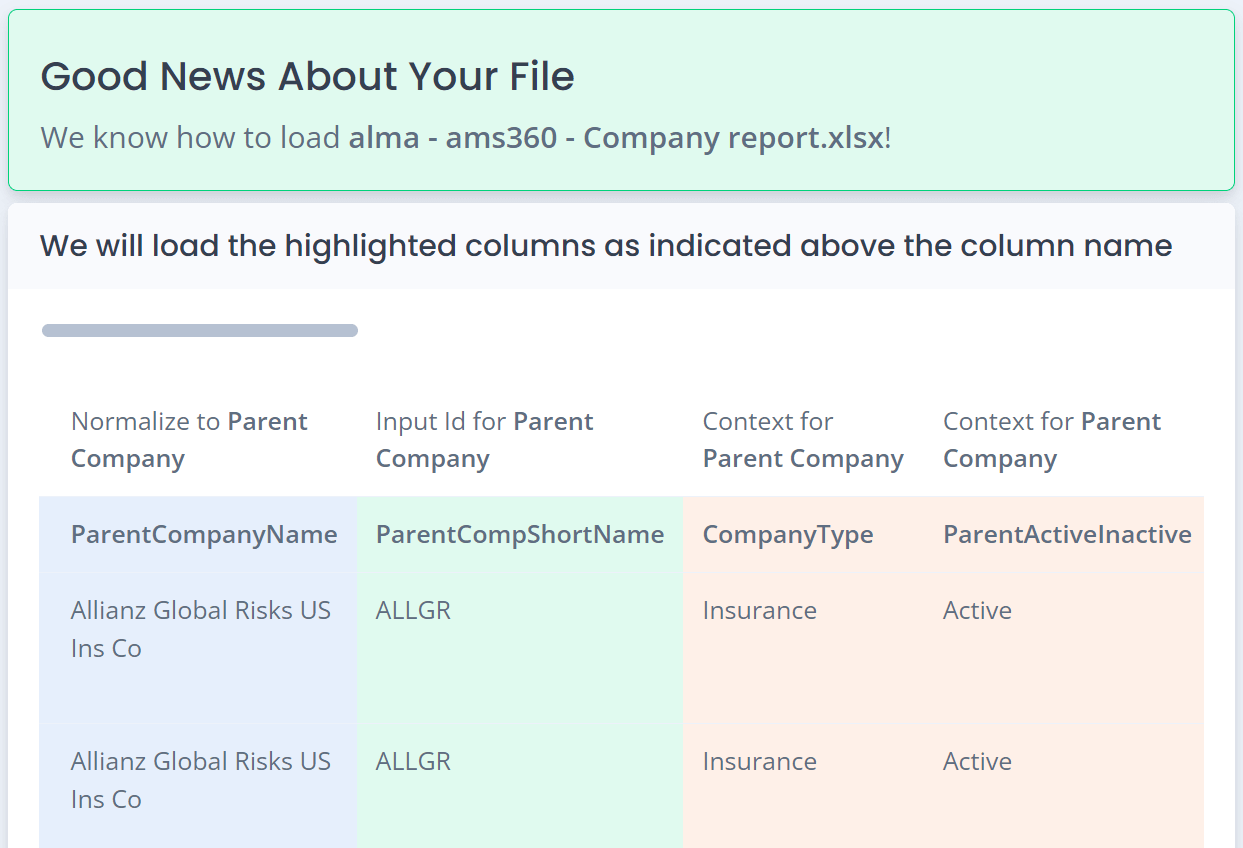
Importing Data To Be Normalized
This process should be designed with business (non-technical) users in mind. The UI should enable the user to upload an Excel file and easily identify which column needs to be normalized. The code then uses that knowledge to populate the INPUT_RECORD table.
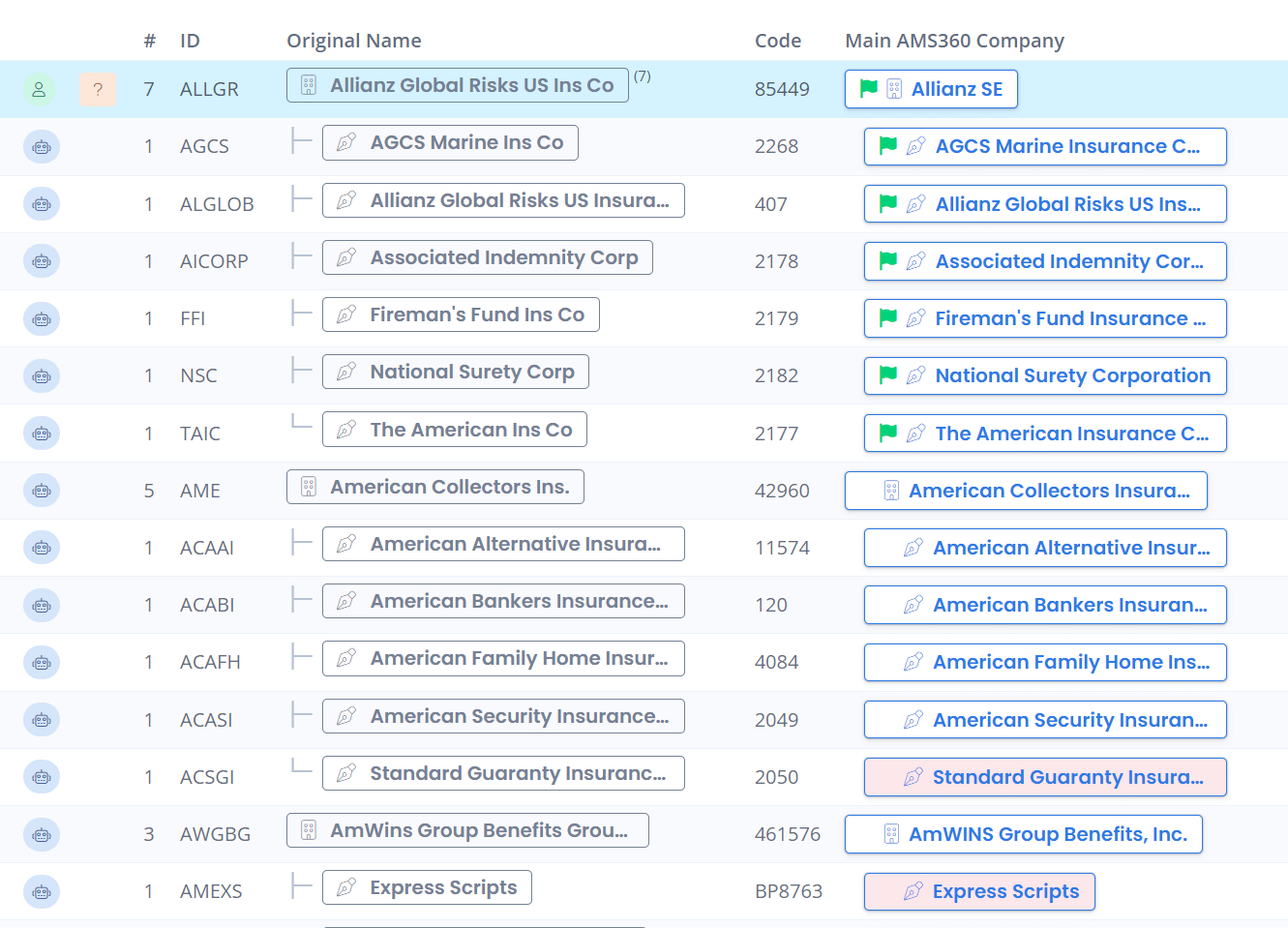
Pointing To Canonical Records
The business user must be able to see all input records that are not yet matched, and efficiently map them to canonical records. You may choose to have them do this one by one.
However, adding Machine Learning functionality will enable the system to automatically link those records that have a high confidence score, or, at the very least, to automatically suggest the top 10 candidates for each input record.
Exporting Mappings as an Excel File (and Via API)
Excel exports allow you to create a pluggable entity resolution platform that is not reliant on heavy system integration. It’s a good starting point if you need to roll out something useful fast.
Bi-directional API integration, on the other hand, allows additional options like near real-time data synchronization – this is particularly helpful when canonical records tend to change in your core system. Data conversion teams will benefit from having access to updated data, as it takes time to complete record likages.
API also allows them to bypass clunky menus and unituitive mapping/import menus in data conversion portals – still a common case for many enterprise systems.

Undoing Certain Mappings or Restoring to a Previous Checkpoint
You need to handle versioning to some degree. Generally, by ensuring that there are checkpoints, you are creating a system that’s non-destructive, and mitigates human errors.
Allowing a “Draft” Mode of Linkage Creation
In most real applications, teams prefer to have a “current” set of linkages. If the data team is preparing an upgrade to a new canonical model set, they should be able to keep such changes separate (and invisible) from the users of the current linkages.
Managing Data Access Rights and Permissions
As your data management team grows, you will want to be able to restrict access and permissions to some subsets of your data to avoid accidental changes that might have an impact on other teams.
Often different people will be in charge of converting data, and managing your golden records.
Implementing Machine Learning (no, it’s not ‘just use ChatGPT’)
Machine learning will enable your entity resolution capabilities to improve over time. Your tool will grow more accurate and sophisticated as it is given more data to work with. Gradually, it will become better at connecting canonical records to new input records that contain mistakes or deviations in formatting.

We recommend that your team uses AWS SageMaker infrastructure to implement the Machine Learning for your entity resolution tool. Since AWS has a large library of tutorials (see https://aws.amazon.com/getting-started/hands-on/build-train-deploy-machine-learning-model-sagemaker). We will not go into the specifics of implementation here.
However, we would like to share one valuable takeaway from our own implementation experience.
We observed that building the initial model and plugging it into the UI on a developer’s machine only accounted for about 5% of the effort we spent on machine learning.
The remaining 95% was in creating robust processes and infrastructure to support the following objectives:
- Keep strict control over deployment of the model to the production environment. This includes finding a way to test a pre-release version of the model, and knowing in advance which aspects will be changed when it is eventually deployed to production.
- Ensure you are able to roll back your model (and revert the relationships it automatically established) in production to a specific prior version
- Have a strict test harness that is quantifiable in reporting of any possible deterioration in predictions compared to a
‘gold standard’input set. - Have a strict test harness that allows upgrades of the training set to the respective model (i.e. the model logic stays the same, but when you upgrade the training set by adding human-done data conversions – let’s say, once per week – the results of predictions should not be worse).
Factor these considerations into your Machine Learning implementation for entity resolution, and you will be well on your way to creating an adaptable, responsive system that can grow with your organization.
Making Entity Resolution User-Friendly and Painless
Anything above was a small part of creating a functional data matching tool in a technical sense. At this stage, it’s just barebone raw functionality.
Remember that you are working with people!
It’s a business process you are designing around, and your end-users have their needs.
Past technicalities, UI, and access comes comfort and streamlining actual work.
Here’s a lesson coming from a team behind a B2B SaaS entity resolution platform: listen to your end-users and understand the business process with its operational quirks.
It really helps you to deliver something useful that makes people happy to work with only when you begin to understand their pains. Naturally, you should also establish who needs to use data in your organization. Different departments or analysts may want to report different things, at various levels of granularity.
In the case of RoecrdLinker, we introduced two quality-of-life features for our insurance industry clients. This is all thanks to the fact that we spent time on understanding what they do, and where they encounter specific issues.
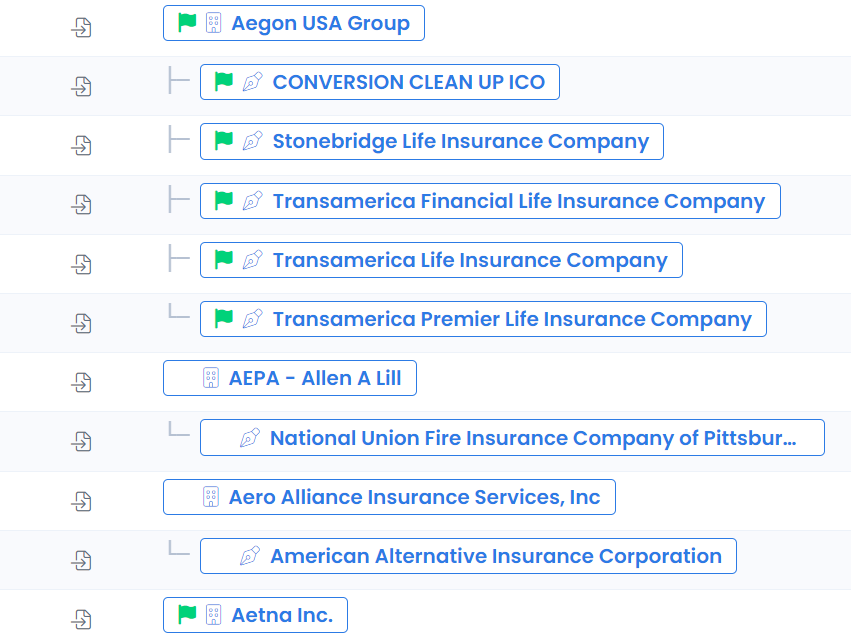
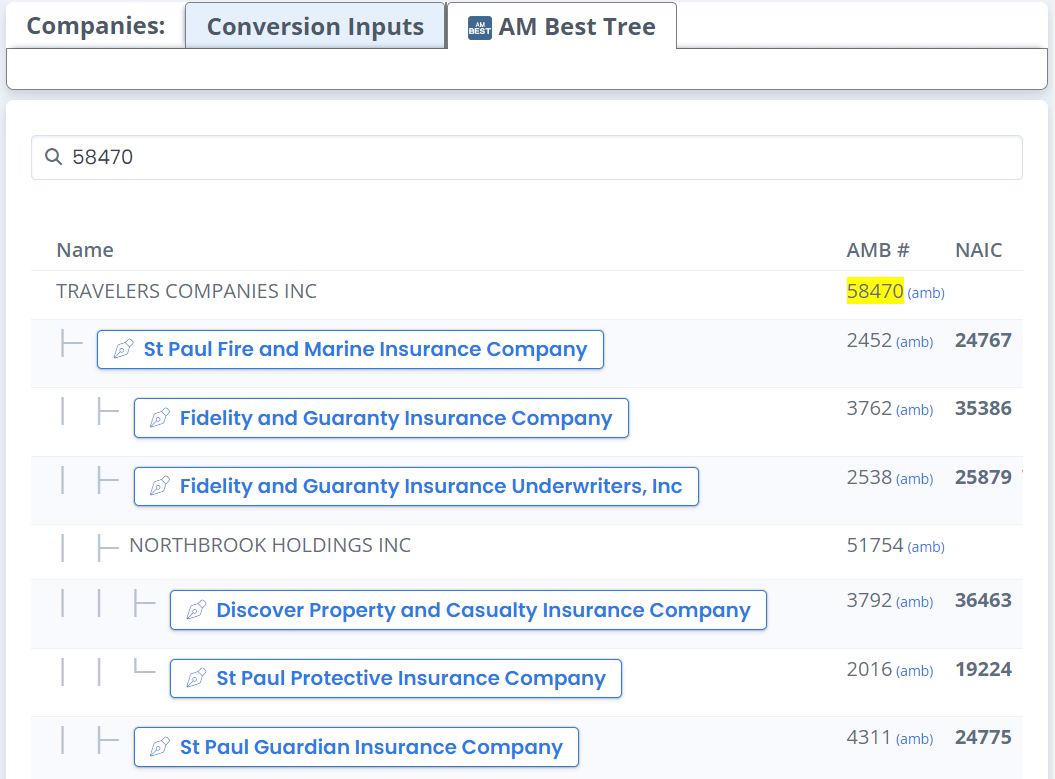
Presenting records in a tree structure to allow data conversion specialists to understand realtionships of what they are linking and what already belongs to a top-level company.
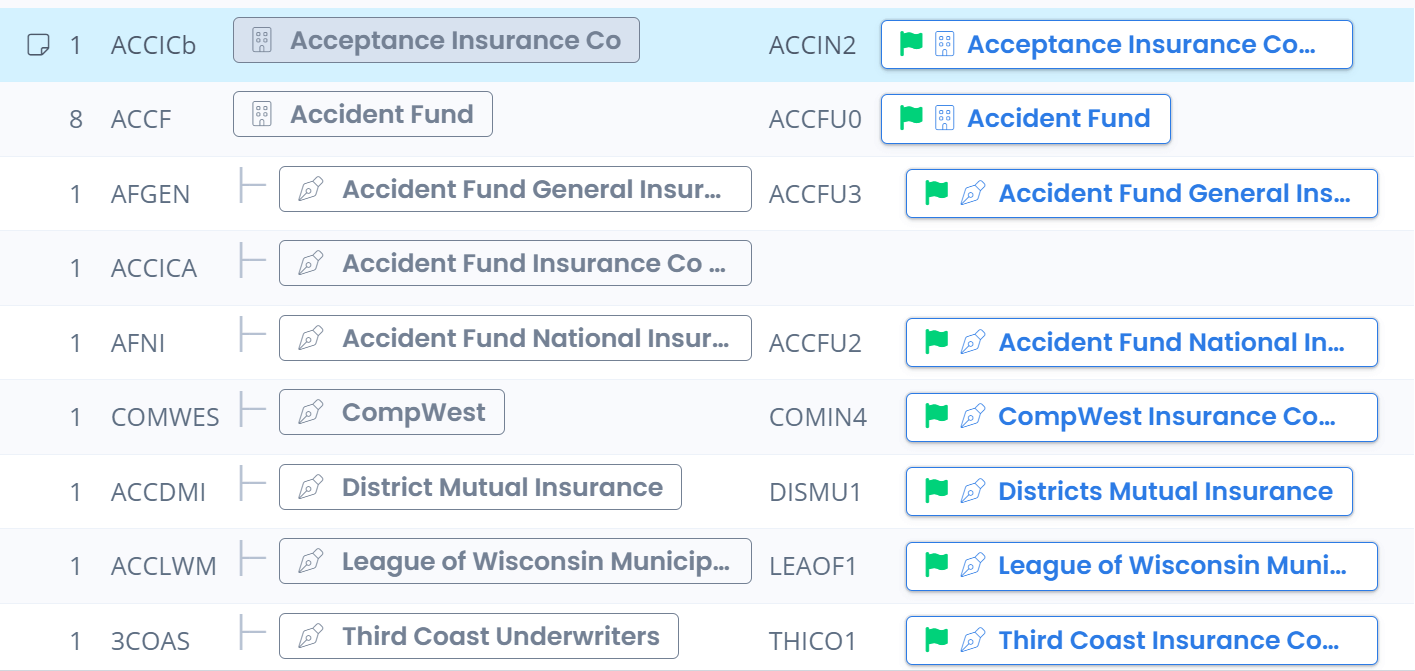
Giving them in-app access to an external source of insurance industry data (AM Best Tree) to further help them in updating and creating canonical records. We have even overlaid their records on this external source of data to help them understand what’s in their sysytems, and where it fits within the industry that relies on relationships between insurance carriers and brokers.
If you want to look into various capabilities that can top record linkage software to make it more helpful – take a look at RecordLinker’s features.
Entity Resolution Software Wrapped Up
Implementing an in-house data matching solution takes planning, patience, a keen understanding of your organization’s data management needs, and a team with the right specialized skills and expertise.
In the end, it will be worth it. An entity resolution system will go a long way toward helping you make the most of your data, and you will see the benefits in nearly every aspect of your business.
- Your analytics and predictions will grow more accurate.
- Your business processes will become more efficient.
- Your employees will be free to focus on doing their jobs well rather than chasing records.
If you plan to start implementing entity resolution software yourself, we are rooting for you. You are heroes, and doing a critical job for your company.
If you have any questions, email 'dev' 'at' recordlinker.com. We are happy to share our knowledge.
More Reading About Machine Learning and Data Management
Do you want to expand your knowledge about ML, MDM, and entity resolution? Building a data-driven organization requires effort, and knowledge of what’s possible. Check these articles to find more inspirations:
- Types and Uses of Entity Resolution Software
- Canonical Model in Data Architecture Explained
- Guidelines For Creating and Managing a Canonical Record Set
- Name Normalization – Matching Companies, Vendors, Suppliers, and More
- Super Customer Data Integration with Entity Resolution
- Multiple Data Sets and KPIs Analysis
If you decide to try RecordLinker and have your data normalized in a few weeks rather than a year, request a demo (click blue button below) and mention this post for a discount.
Happy Record Linking!


