Data Mapping Tools and Techniques for Enterprise Scale

Szymon Zak
December 24, 2024

Data mapping is essentially telling your destination system or data amart that input records ABC, BCA, DEF mean XYZ in your destination. What data mapping really tries to tackle is a process called entity resolution.
Behind the sleek demos and PowerPoint slides, data teams fight a hidden battle. They map thousands of records between systems, standardize company names that evolved over decades, and untangle webs of relationships built through years of mergers and acquisitions. Their tools actively work against them, forcing manual processes where at least a degree of automation should exist.
The reality of their work is by no means nice. Here are some insights into how this line of work looks and why it is not just simply about moving data from point A to B while just mapping fields. Listen to what our founder, Roman, has to say:
The Unseen Data Heroes of Insurance – Listen to Our Guest Episode
Our founder, Roman Stepanenko, shares insights into challenges of data administrators and data conversion teams in insurance.
Discover the gaps in the process, and the reality of manual workflows of insurance's data people. They are some of the most hard-working and unnoticed 'silent teams'.
Data conversion analysts, business systems analysts, implementation specialists, and data admins keep large brokers going after agency acquisitions.
Understanding the Data Mapping Challenge
Data mapping transcends simple field matching between systems. It demands deep understanding of complex business relationships, recognition of naming patterns, and preservation of critical business context during transitions.
Enterprise mapping projects take many forms:
- Post-merger system consolidation forces teams to reconcile different data models shaped by years of separate evolution.
- Regional office standardization requires handling multiple valid versions of the same entities.
- Vendor reconciliation means untangling relationship webs that grew more complex over time.
- Historical data cleanup for reporting demands understanding how business rules and structures changed through the years.
Typical Data Mapping Tools
Organizations often tackle record matching with tools built for simpler tasks. This mismatch creates endless headaches for data teams trying to preserve business context in data mapping. Each available option brings its own limitations and trade-offs.
System Vendor Tools
Core system vendors provide basic conversion portals that chain users to manual, record-by-record processing. These interfaces split related data across multiple screens while providing minimal validation. They usually ignore critical business context, offering bare transformation and load functionality that allows mapping data into a specific system. Oftentimes they are made to address data migration and mapping when for the vendor’s largest competitor.
Custom Scripts
Many organizations turn to writing custom code for mapping projects. This creates maintenance nightmares as knowledge becomes locked in individual developers’ heads. When those developers leave, teams inherit unmaintainable scripts that no one fully understands. Too often, classic scripts are one-offs made to solve a very specific problem or handle legacy system’s data.
Mapping in Basic ETL Tools
Traditional ETL platforms handle straightforward field-to-field mapping but crumble when confronted with real business data complexity. They can’t recognize different valid representations of the same entity or handle evolving parent-child relationships. These tools are fairly rigid and typically lack the ability to learn from past mapping decisions or adapt to industry-specific patterns. Moreover, they are sold as universal power tools – which may not respect many minor but important contextual differences between data models.
Then there is the omnipresent use of Excels, which are not great for mapping, horrible for consistent data standardization, and overall useless for serious large-scale entity resolution.
Modern Data Mapping Techniques
Moving beyond crude automation and manual spreadsheets, modern approaches tackle real business complexity. These techniques recognize that business data carries context and meaning beyond simple field values. They adapt to how organizations actually work rather than forcing artificial standardization. Three key approaches shape the current evolution of mapping tools.
Pattern-Based Matching
Advanced mapping tools must recognize the natural variation in how entities get named and structured across systems. Company names shift between long and short forms. Industries develop their own abbreviation patterns. Regions adopt different naming conventions. Historical records reflect old company names and structures. Modern tools need to handle this complexity without forcing artificial standardization.
Relationship Mapping
Business data tells the story of organizational evolution through webs of relationships. Modern mapping tools must preserve these crucial connections. Parent companies acquire subsidiaries. Vendors become customers. Departments split and merge. Each change leaves its mark in the data, and each mark carries meaning that must survive system transitions.
Learning Systems
Effective mapping tools learn from past decisions to automate routine work while flagging complex cases for review. This goes beyond simple pattern matching. The system must understand industry context, recognize confidence levels in suggested matches, and identify exceptions that need human expertise. Most importantly, it must augment rather than replace human judgment.
Why Traditional Approaches Fall Short in Data Mapping
Data teams across industries fight a daily battle with inadequate tools and broken workflows.
In the trenches of enterprise data management, system admins and data conversion specialists waste countless hours on manual data entry, wrestling with legacy interfaces that split simple tasks across dozens of screens. This isn’t just inefficient—it actively damages data quality and team morale.
Making It Simple But Inefficient: The Excel Trap
Organizations default to spreadsheets for data mapping because they’re familiar and readily available. But Excel wasn’t built for enterprise data mapping.
Spreadsheets break down spectacularly when handling complex hierarchical relationships or broad variations in naming standards. Data conversion teams and business systems analysts end up with dozens of versions of mapping files, each containing different stages of work and conflicting changes.
A manufacturing company might find itself tracking six slightly different spellings of the same vendor name across years of purchase orders. A large insurance broker might discover 800 unique ways to write “Philadelphia Indemnity Insurance Company” along years of agency acquisitions
Think not just about spelling variations and misspellings, but also about permutations, shortened words, abbreviations, prefixes etc.
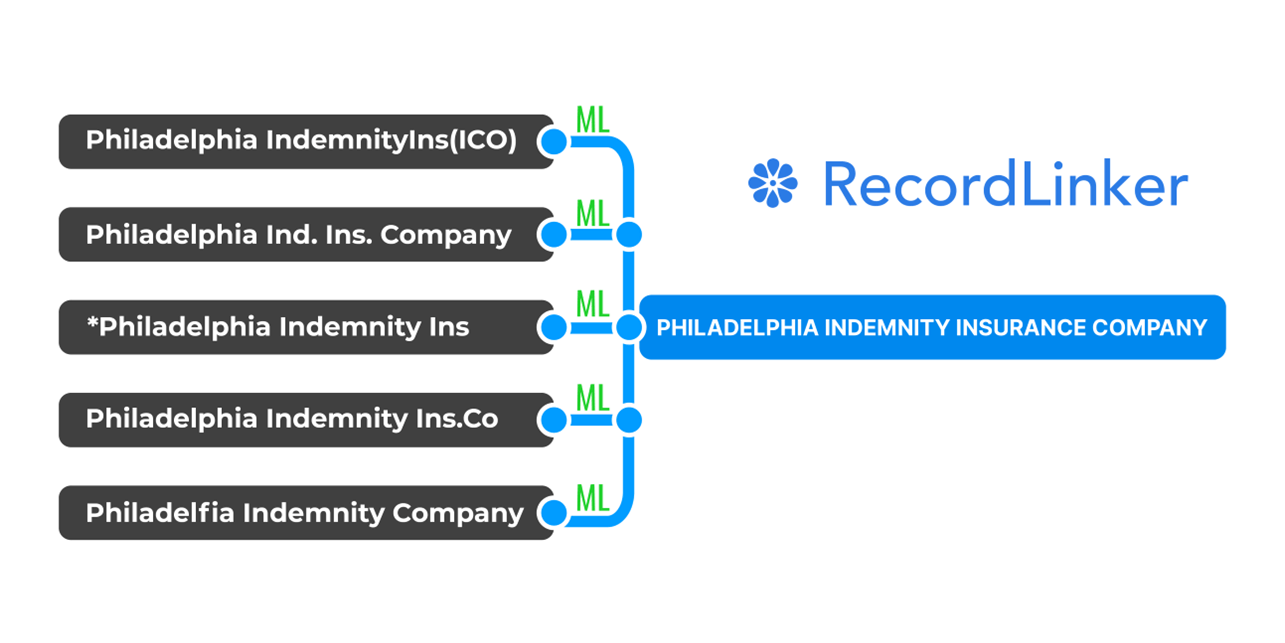
Excel offers no meaningful way to handle these real-world complexities.
Often times your vendor provides a portal for data mapping, data conversion etc. this is either a module in your core system, or an independent connected portal.
Your Tech Vendor Doesn’t Care: The Legacy Portal Problem
Core system vendors focus development effort on client-facing features, leaving administrative interfaces as an afterthought. The resulting portals force data through byzantine workflows that don’t support data mapping. They might require:
- Opening multiple windows to view related data.
- Clicking through nested menus for basic settings.
- Manually copying data between screens.
- Repeating the same actions hundreds of times.
Core systems control your business – but their admin tools feel like an afterthought built fifteen years ago and never touched since.
These interfaces actively prevent efficiency.
They offer no bulk operations, no meaningful guidance for business context, and no way to collaborate effectively. The tools are so hostile to productivity that teams resort to building crude workarounds with spreadsheets and custom scripts, to only then enter data manually into these portals.
Vendor portals only provide basic validation (e.g. for required fields), so they won’t tell your data analysts that they may have mapped 2 incorrect entities, or mapped something that should by all means be kept as seemingly duplicate entries.

Data Mapping and Real-World Data Complexity
The Myth of Perfect Standardization
Enterprise data doesn’t fit into neat boxes. Different systems maintain different data models because they serve different business needs. A CRM system organizes customer data for relationship management. Finance systems track the same customers by billing terms and credit status. These aren’t arbitrary differences — they reflect essential business requirements.
What looks like messy data from disparate sources often represents necessary adaptation to business reality.
If you are dealing with post-M&A integrations and system migrations, the data models of 2 systems coming from different solution vendors are bound to differ a lot. They might be based on different relationships, hierarchies, attributes of entities, business rules etc.
What looks roughly the same in the front-facing user interface, differs a lot in the background.
The Hidden Structure of Business Data
Real enterprise data contains complex relationships that simple field mapping can’t capture. Consider these common patterns:
Records that look like duplicates might represent legitimate business relationships. A vendor appears twice because they act as both supplier and customer. A company shows up under multiple names because different divisions handle different product lines.
Business context is what drives how data in your systems is used. It serves operational needs, and your data teams are invaluable for navigating these peculiarities.
Moreover, reference data evolves over time as business needs change. Company names get updated, relationships shift, and new categories emerge. Systems accumulate special cases and exceptions that made sense in specific business contexts.
Time-based variations create additional complexity. Historical records might use old company names or different classification systems. Mergers and acquisitions introduce whole new sets of naming conventions and business rules specific to differing systems.
Building Modern Mapping Solutions
Fixing enterprise data mapping requires two core capabilities: light integration with your systems and intelligent automation that respects human judgment. Without direct system access, teams waste time on manual imports and exports. Without smart pattern recognition, they drown in repetitive decisions. Success demands both technical depth and practical usability.
If you want a deep dive into creating your own entity resolution software, learn from our experience.
The Foundation: System Integration
Modern mapping tools need direct API connections to core systems. This enables:
- Real-time synchronization that eliminates manual import/export cycles.
- Automated validation that catches errors early.
- Bi-directional updates that maintain system consistency.
- Draft modes that allow work review before production changes.
But API integration alone isn’t enough. Tools need to understand system-specific data models and business rules. They must respect system autonomy while enabling efficient data management.
Machine Learning for Augmenting Human Judgment
ML serves a crucial role in modern mapping tools – not by replacing human judgment, but by making it more efficient. Effective ML systems:
- Learn patterns from completed mappings to suggest matches for new records.
- Recognize variations in naming and formatting.
- Calculate confidence scores to prioritize human review.
- Adapt to organization-specific patterns over time.
- Handle context-specific matching rules.
Machine learning should reduce manual work, not replace human expertise.
Making Data Mapping Work in Practice
The reality of enterprise data mapping hits hardest during mergers and acquisitions. A typical scenario: Company A buys Company B. Both use the same core system, but with different data standards and conventions built up over years. Company A’s data team now faces mapping thousands of records between systems, often working late nights to meet migration deadlines.
The Truth About Implementation
Data teams need three things to succeed:
First, they need direct access to their systems’ data through APIs. Without this, they waste time on manual exports and imports. API access lets them pull fresh data when needed and push approved changes back to production.
Second, they need tools that understand their business context. Insurance brokers map carriers differently than manufacturers map vendors. Tools must adapt to these industry-specific needs rather than forcing generic approaches.
Third, they need interfaces built for efficiency. Data administrators often work with hundreds or thousands of records at once. They can’t waste time clicking through multiple screens for each change.
Your data team already knows how to map and improve your data.
They just need better tools than a vintage interface.
Real Quality Control
Quality in data mapping doesn’t come from rigid rules – it comes from giving data teams the right information at the right time. This means:
- Showing hierarchical relationships so teams understand how records connect.
- Displaying industry reference data alongside internal records.
- Catching obvious errors before they hit production.
- Letting teams work in draft mode until changes are ready.
Your data teams are your main line of defense against mistakes. They just know how your industry and tech ecosystem work.
A proper mapping tool acts like a skilled assistant, pointing out potential issues while letting the expert make final decisions.
Making Machine Learning Useful
Machine learning helps most when it focuses on specific, well-defined problems. In data mapping, this means:
- Learning from past mapping decisions to suggest matches for new records.
- Identifying patterns in how your organization names and categorizes data.
- Making it possible to flag unusual mappings that might need extra review.
But ML should never force decisions.
It works best as a “first pass” that helps data teams work faster.
Measuring Real Impact
Skip the fancy metrics. Focus on what matters:
- How many records can your team process per day?
- How many mapping errors make it to production?
- How often do teams work overtime to finish mappings?
- >How long does it take to train new team members?
These numbers tell you whether your tools actually help or just add complexity.
RecordLinker: Flexible, User-Friendly ML for Data Mapping
Are you acquiring businesses, migrating operations, or consolidating business systems? Do you have a system that suffers from duplication in entities due to persistent data migrations or data entry volume?
We are primarily known for helping some of the top 100 US P&C brokers with their data conversion (mapping data from one acquired system to the destination system post-M&A).
RecordLinker is not an off-shelf product. To really help you, we need to understand your data model, the flavor of your problem, goals, and opportunities for integration to preconfigure our system. Only then we can deliver exceptional value.
Please, feel free to contact us for a demo.
RecordLinker gives an actual useful environment with interface that help people reorganize their work efficiently when compared with native tools and spreadsheet-heavy labor.
This systematizes your business process with our ML added on top for boosting the throughput.
We provide a no-cost trial, allowing your data team to see that meaningful positive change is finally possible.
Enterprise-Scale Data Mapping Wrapped Up<
Enterprise data mapping needs tools built for reality, not theory. This means:
- Building interfaces that respect how data teams actually work.
- Connecting directly to core systems through APIs.
- Using machine learning to reduce manual work, not eliminate human judgment.
- Focusing on industry-specific needs rather than generic solutions.
The future of data mapping isn’t about grand visions of perfect standardization. It’s about giving skilled professionals the tools they need to work efficiently. Everything else is just noise.
Data teams don’t need perfect tools. They need practical ones that solve real problems – by bridging gaps in usability and collaborative workflows.
Suggested Reading about Entity Resolution and Data Standardization
Take a look at our recommended reading list for practical and easy-to-understand resources. We cover topics in-depth to help you gain greater understanding of all things related to entity resolution. Prepare for the right choices about your data management:
- [Guide] Data Conversion Explained
- Normalizing Names of Vendors, Suppliers, and Companies
- Data Normalization: What You Need to Know About Software
- Types of Data Matching Tools: Deterministic vs. Probabilistic Approach
- Centralized MDM and Single Source of Truth Can Disrupt Your Data
- Data Integrity During Ongoing Data Management and Migrations


