Post-M&A Integration: Making IT System Consolidation Effective

Szymon Zak
December 8, 2024

Reality of Post-M&A Integration and Business Systems
This challenge becomes particularly problematic in sectors, which rely on M&A as a method of growing business e.g. insurance brokerages acquiring agencies that run different Agency Management Systems. Before M&A, an insurance agency runs its operations as an independent organization, resulting with a system full of coverages, policies, related writing companies, and employees.
Traditional M&A playbooks may treat system consolidation as a simple set of technical steps – export data from source systems, transform it to match the target format, import it into the destination platform, and go live. This view lacks the complexity of core business systems, their intricate data relationships, and effort required to perform just a single migration.
It sounds simple to decision makers and business people detached from work with data.
Why is it so complex to migrate data from system A into system B?
The answers to that are data models, for systems of a different kind. and standards of data governance as well as data quality, both for different systems and installations of the same system.
The Deep Business Complexity of Data Models
What looks simple on paper – moving data from system A to system B – hides layers of structural complexity.
Some systems create duplicate entities like companies to handle different business relationships. A vendor might appear twice – once as a supplier and once as a customer. Other systems might maintain a single company record and use relationship tables to connect it to multiple business functions. These different approaches to modeling business relationships create complex mapping challenges when systems merge.
Different systems also implement their own data validation rules. A customer record may have three years of transaction history in one system but only basic contact details in another. Required fields shift between systems – one might demand a D&B number for every company while another treats it as optional. These fundamental differences in data requirements make simple field mapping inadequate.
Years of real-world usage shape how teams use these systems. Administrators create temporary records for testing integrations. Special handling flags mark problematic accounts. One-off projects leave behind records that made sense at the time but now lack context. Each system accumulates its own specialized data practices that reflect past business needs. Data conversion teams must understand these organic patterns to merge systems effectively.

Why Post-Merger System Consolidation Breaks Down
Core business systems shape themselves around specific operational needs over years of use. Each system has its own way of representing business entities, relationships, and hierarchies.
Differences in data models create layers of friction and require good understanding of data models on both sides. One system may rely on cloning entities (like companies) to assign them under a parent entity. Another system may just rely on many-to-many relationships and reuse the same entity agnostic to its relationships.
Even integrating two installations of the same system comes with having to map differently spelled company names (e.g. vendors, suppliers, intermediaries). The data model may remain the same, but you still need to point each record from the acquired source system to inform your destination system that the source record ABC means XYZ in your system.
For some critical records there are multiple linked tables that will “follow” the mapped entity. A mistake here means that any subordinate attributes and more granular records will get misassigned. This is one reason why your teams shouldn’t be working on data mapping in Excel or vendor portals that won’t question strange mapping choices.
These structural differences run deeper than simple field mapping. Validation rules, mandatory attributes, and business logic create a web of dependencies that resist straightforward translation. A customer record that passes all checks in the source system might fail basic validation in the target platform. Sometimes one system won’t even have required fields for a certain type of an entity.
Perpetually created real-world datasets are hardly ever structured and accurate.
Years of operational use compound these challenges through natural data quality issues. Post-integration M&A is one of these occasions when all piled up data integrity and accuracy issues reveal in full might.
Mistakes collect over the years, existing company names and DBAs evolve, relationships change, subsidiaries change, and information grows stale. What started as a clean data model gradually accumulates exceptions, special cases, and workarounds like “DO NOT USE” or entities spontaneously created for some one-off project or tests run in production.
Merging real-world datasets demands more than technical transformation – it requires deep business context and judgment.

Data Teams’ Struggle in Post-M&A Integration
Data conversion teams and business systems analysts face the ugly part of post-merger platform consolidation. M&A playbooks never mention it, and this is something you need to understand to enable those people. They are not just working on data, what accurately describes their task is data labor.
Here is why post-M&A platform consolidation is not fun.
Conversion specialists grapple with thousands of data records that resist simple categorization.
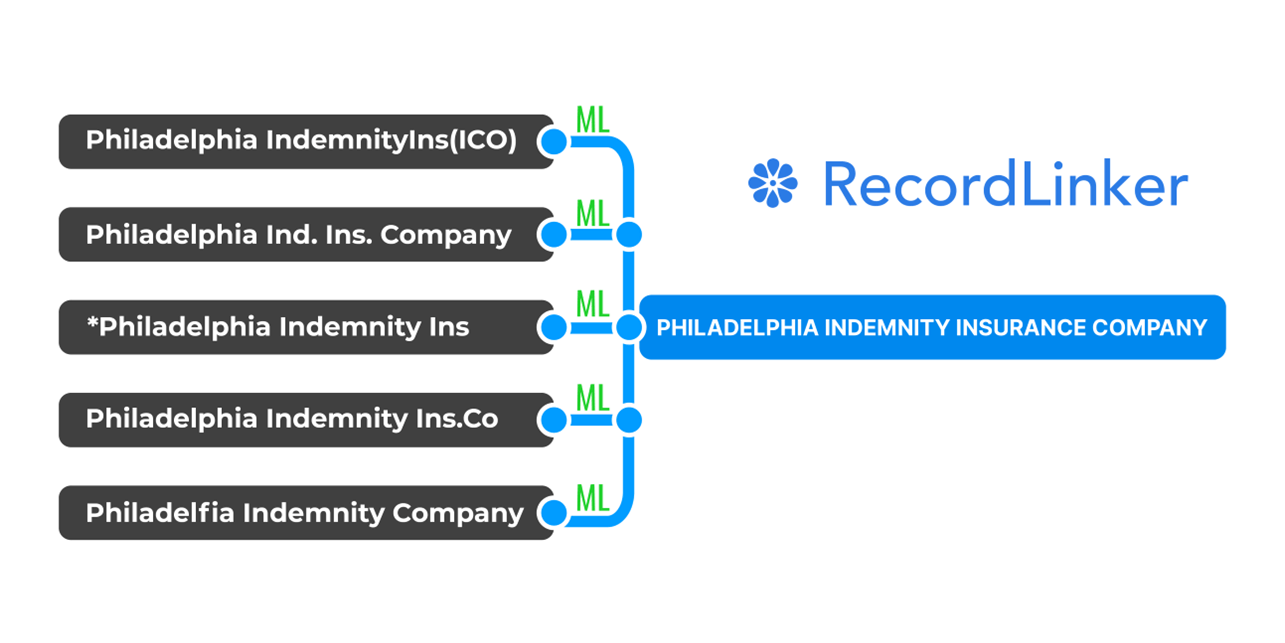
A manufacturing company in the source system may appear under six slightly different names – each tied to different vendor contracts and purchase orders. An insurance carrier may show up as both “Travelers” and “The Travelers Indemnity Company” across years of policy data. The said entity may not even exist in your destination system or appear under a wildly different name.
The Unseen Data Heroes of Insurance – Listen to Our Guest Episode
Our founder, Roman Stepanenko, shares insights into challenges of data administrators and data conversion teams in insurance.
Discover the gaps in the process, and the reality of manual workflows of insurance's data people. They are some of the most hard-working and unnoticed 'silent teams'.
Data conversion analysts, business systems analysts, implementation specialists, and data admins keep large brokers going after agency acquisitions.
Data teams navigate complex relationships between records under intense time pressure. Business units need access to both systems during transition periods that stretch longer than planned. Sales teams must quote new business while accounting reconciles historical transactions. Discovering relationships in data means hours spent working late to meet migration deadlines.
M&A integration plans often underestimate this complexity. The assumption is that data conversion means as little as matching pairs of fields between systems. The reality involves understanding why a system tracks three variations of the same vendor record, which relationships matter for daily operations, and how to preserve critical business context during conversion. Data teams make hundreds of these decisions while racing against project timelines and maintaining system stability.
For every completed M&A integration project, there is at least one person who battled with data conversion Excels at 2 a.m.
You Data Teams Are Veterans Without Equipment
If data mapping doesn’t happen in spreadsheets then somewhere in your system there might be something you most likely never heard about.
It could be a hostile data mapping menu with mile-long dropdowns in a vintage UI. Sometimes it’s a separate – equally obsolete – portal your system vendor is ashamed to even mention, or pitches it as a next-gen feature (for early 2000s standards). It’s not fun for your data people though, but often it’s all they have.
Data conversion specialists and business system analysts know this reality all too well. What looks like a simple data migration on paper turns into months of manual mapping, late night marathons of reconciling mismatched records, and huge, huge stress. The human cost often goes unnoticed, and they are not the first in line to be appreciated.
We are not making it up for dramatic effect, while RecordLinker helps data conversion teams, we still see their login times during spikes in M&A activity and following integration projects.
Manual Mapping Methods Disrupt System Consolidation
Most organizations have to approach system consolidation through brute force – units of analysts armed with Excel spreadsheets manually mapping records between systems. What escapes the functionality of mapping portals and spreadsheets turns into fiddling with one-off scripts or custom solutions that took a quarter to complete to solve the problem, and are put to rest soon after somewhat solving it. This approach fails to scale and produces inconsistent results.
Addressing data problems in platform consolidation is not just about technology. It starts with enabling data teams with user-friendly tools to use their expertise.
You can only get so far with exact matching, partial matching, and regular expression tricks. Realistically, you may get 15-30% done. Subtle variations in company names, formatting differences, and human error guarantee mapping mistakes.
Technical leads find themselves trying to automate processes that rely heavily on human judgment and context. Traditional tools force them to choose between rigid automation that breaks on edge cases and manual processes that don’t scale. Custom scripts and traditional ETL tools offer partial relief but miss the fundamental challenge.
Core system users have incomprehensible creativity for creating hundreds of case-insensitive permutations for 3-4-word-long names.
For this reason, it’s context-aware decisions that define real-world consolidation work.
New Model for Supporting System Consolidation and Data Mapping
System consolidation demands tools that help data teams comply with technical reality and understand business context. Rather than forcing rigid standardization, next-generation platforms must support the natural variability of data in business systems while enabling quick wins, usability oriented at throughput, and easy integration.
This means moving beyond simple data transformation to create intelligent data normalization solutions that:
- Connect directly with core systems through API integration, maintaining real-time synchronization with destination records. This preserves system autonomy while enabling controlled data flow.
- Support human judgment through Machine Learning that suggests matches based on training data and user input. Such systems learn from completed data conversion projects, continuously improving their ability to handle variations and special cases.
- Provide proper workflow features for conversion teams to collaborate effectively. This includes features for project separation, reviewing suggestions, handling exceptions, and maintaining clear audit trails of decisions.
- Preserve business context by showing hierarchical relationships and integrating with third-party industry reference data. This allows Conversion specialists can see the full picture when making mapping decisions.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

How RecordLinker Aids Data Mapping Post-M&A Integration
RecordLinker transforms post-M&A data mapping through a combination of Machine Learning and usability.
Our Machine Learning capabilities can automatically suggest matches for company names, vendors, lines of business, and other critical entities. These ML models understand variations entity names and their business hierarchies. The ML models only suggest matches that pass the confidence threshold. As a result, instead of starting from zero, conversion teams begin with records pre-mapped for further work.
Everything our Machine Learning does is subject to review, edits, and approval from your data team.
The key area of improvement RecordLinker provides is about creating a unified workspace where data conversion specialists can:
- Divide work into assignable projects, separating entities by domains.
- Collaborate on complex mapping decisions with thanks to labels, comments, and attachments.
- View the entire list of entities from your system.
- See hierarchical relationships between entities if applicable (e.g. systems based on parent-child structures).
- Work in draft mode before committing changes to production systems without any need for manually versioning Excels.
RecordLinker relies on bi-directional API integration with your destination system. This means conversion teams can start mapping data immediately – using as little as exported files from the source system – then seamlessly sync their work into your destination system. There is no need to wait weeks for heavy ETL integration with the source system or restoration of its database’s backup.
The result is a dramatic reduction in project timelines – what traditionally takes weeks of manual effort can often be completed in days.

Post-M&A System Consolidation Wrapped Up
Organizations need to invest in sustainable integration capabilities and focus on improving the process involving humans. This means:
Building dedicated conversion teams with both technical skills and business knowledge. These specialists need to understand system architectures and operational realities.
Creating clear governance frameworks that define how systems interact during and after consolidation. This includes establishing authorities, workflows, and quality standards.
Investing in proper tools that support the full consolidation lifecycle. Manual spreadsheets and basic ETL won’t scale for organizations pursuing growth through acquisition.
Maintaining focus on operational continuity throughout the integration process. The business must keep running while systems merge.
Pre-Conversion Assessment
Your conversion team needs clear answers about source systems. How many active users rely on each system? What critical business processes depend on system data? Which records must move to the target system? What user moved from the previous system will be looking for? What data quality issues exist in source systems?
Data Readiness
Source system administrators should address known issues before conversion. This means cleaning up duplicate records, updating outdated information, fixing broken relationships between entities, and documenting special cases and exceptions.
System Access
Technical teams need proper system credentials like API access for automated data extraction and admin rights for record manipulation. They would benefit from having a test environment access for validation. Having system backups in reach and ready goes without saying.
Conversion Process
Define your conversion workflow. How will you handle exceptions? Who approves mapping decisions? What quality checks occur before final import and go-live? How do you validate successful conversion?
Business Continuity
Plan for operational impact: when will users lose source system access? How long will the conversion take? What contingencies exist for failed transfers? How will you handle post-conversion support? How will users of the old system be moved to the new one and gain access? How will you onboard them? What questions could they have about the new system?
Manual work and human oversight is still needed there. There are no miracle solutions that work at 100% accuracy.
Suggested Reading about Data Normalization and Management
Take a look at our recommended reading list for practical and easy-to-understand resources to help you establish good data practices in your organization. Proper data management is not simple – learn foundational concepts to discover helpful solutions to your data challenges.
- Data Integrity During Ongoing Data Management and Migrations
- How Single Source of Truth Can Work Against Core Systems
- Comparing Data Governance and Master Data Management
- Standardizing Vendor, Supplier, and Company Names
- Data Normalization: What You Need to Know About Software
- Types of Data Matching Tools: Deterministic vs. Probabilistic Approach
Problems with Data Management and Migrations?
Are you acquiring businesses, migrating operations, or consolidating business systems?
We are primarily known for helping some of the top 100 US P&C brokers with their data conversion (mapping reference data from one acquired system to the destination system post-M&A).
RecordLinker gives an actual useful environment with interfaces that help people do their work efficiently when compared with native tools and spreadsheet-heavy labor. This systematizes your business process with our ML only being added on top for further increasing the throughput.
You can reliably cut conversion project times with ML from weeks to days!


