How Machine Learning Overcomes Data Linkage Inflexibility
Roman Stepanenko
January 7, 2024
Machine learning offers an alternative approach to data linkage. Instead of using a rigid set of rules, machine learning algorithms can learn from data to identify which records should be linked.

Many organizations have data spread across multiple silos, databases, or data warehouses. In order to make sense of this data, it is often necessary to link records from different sources that refer to the same real-world entity.
For example, a customer might have a record in one database with their name, address, and date of birth, and a separate record in another database with their name, email address, and phone number. To gain a complete picture of the customer, you will need to find a way to link these records.
There are a number of ways to approach data linkage, but one of the most popular is to use a set of rules, or a schema, to determine which records should be linked. This approach can be effective, but it can also be inflexible.
If the schema is not well designed, it can miss some links, or it can create false links.
Machine learning offers an alternative approach to data linkage. Instead of using a rigid set of rules, machine learning algorithms can learn from data to identify which records should be linked.
In this article, we will take a closer look at the benefits of machine learning for data linkage systems.
What Makes Traditional Data Linkage Systems Inflexible?
Traditional rule-based data linkage systems might function well in a perfect world where data is always logged accurately and formatted in a consistent way. But in our real world, most organizations struggle to standardize data entry and prevent human error from contaminating datasets.
This is an overwhelming challenge in sectors such as public health sector where data needs to be managed across many diverse organizations.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

However, even an organization’s internal data is prone to messiness, especially when teams or individuals have their own systems for tracking it. For example, two internal records might list the same person’s name as “John Smith” and “J. Smith”. Or, they might list one person’s date of birth as “01/01/1980” and “1/1/80”. In these cases, a traditional data linkage system would likely not consider these records to be matches.
Strict rules can lead to false negatives, where two records that should be considered matches are not identified as such. On the other hand, rules that are too lenient may result in false positives, with records being linked erroneously.
Since real-world data is quite often messy and noisy, such errors occur frequently. This can lead to incorrect conclusions being drawn about important data, and undermine effective decision-making.
How Can Machine Learning Help?

Machine learning approaches to data linkage overcome the inflexibility of traditional systems by learning how to identify matches based on a set of training data. This training data can be generated by humans who manually label pairs of records as matches or non-matches.
Once the training data is available, a machine learning algorithm can be used to learn a function that maps records to a matching score. This function can be used to compute the similarity between any two records, and records with a high similarity score can be considered matches.
Data linkage systems equipped with machine learning have a number of powerful advantages over traditional solutions.
Machine Learning Benefits in Data Linkage
Flexibility for Imperfect Data
Machine learning algorithms are designed to deal with complex data and can learn from data that is not clean or perfect. This makes machine learning a more versatile solution for data linkage than traditional methods.
Machine learning can be used with data that is not well structured. For example, if two records only have a few common fields, or if the data is in a free-text format, it can be difficult to define a set of rules that will reliably link the records.
In other words, machine learning systems can learn to identify matches that would not be obvious to a traditional rule-based system. This gives it much greater flexibility and the ability to account for a wider range of differences between records.
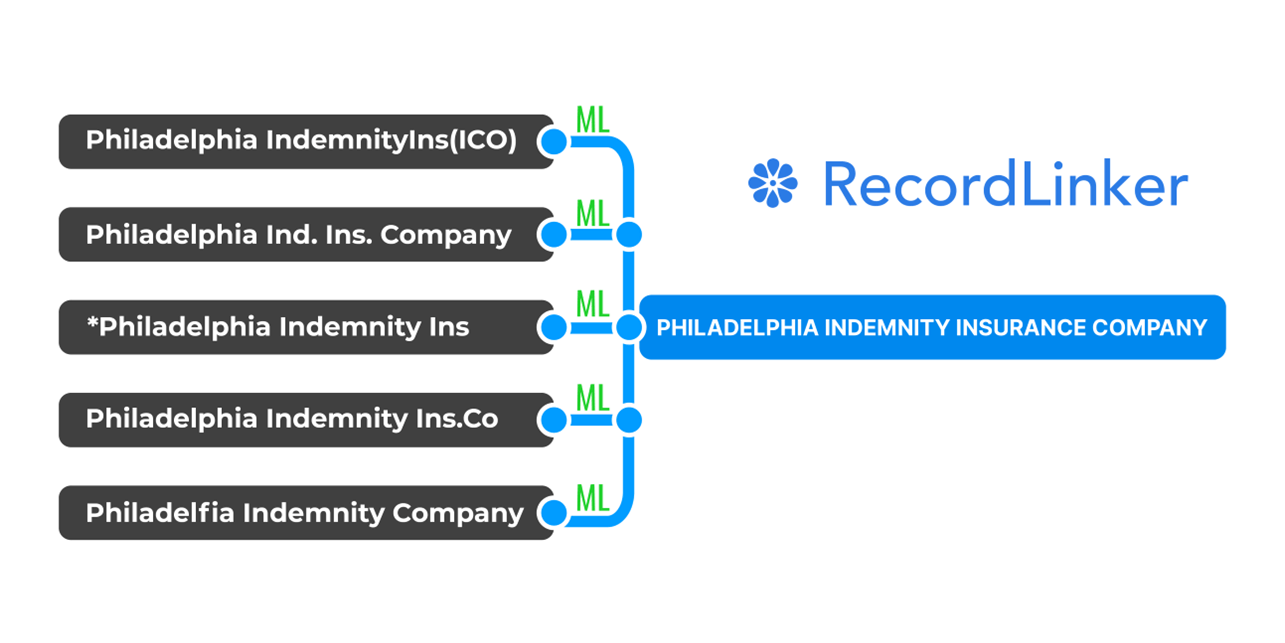
A traditional system might fail to find a match between the records “John Smith” and “J. Smith”, even though they represent the same person. A machine learning algorithm, on the other hand, could learn that these records are matches even though they differ in the way the name is recorded.
With more flexible machine learning approaches, it is possible to build systems that are more accurate and capable of finding a wider range of matches.
Improved Data Conversion Speed
Traditional methods for data linkage are typically slow, often taking days or even weeks to complete. This can be a major problem when trying to process large data sets in a timely manner. Machine learning can overcome this issue by automating data linkage, massively increasing the processing speed.
Organizations looking for lightning-fast processing speeds can parallelize machine larning. This means that multiple processors can work on the same problem at the same time. This can enable considerable speed increases, especially when using GPUs (graphics processing units) which are designed for parallel processing.
Speeding up the data linkage process has a number of benefits. It allows for more data to be processed in a given time period, which can lead to improved decision making. It also makes it possible to process data in near-real-time, which is critical for applications such as fraud detection.
Linkage Scalability
Finally, a machine learning approach is much more scalable to large datasets. Traditional data linkage systems often require a lot of human effort to create rules for matching, and these rules can be difficult to maintain as the data changes over time.
Machine learning approaches can be automated and can learn to match records without any human intervention.
If your organization deals with a lot of data, or if that data is constantly changing, a machine learning approach can be a much more efficient way to maintain your data linkage.
Make Your Data Work for You

Integrating machine learning into your data linkage process can go a long way towards helping your organization become data-driven.
Machine learning can improve the accuracy of data linkage by learning from past linkages and identifying new patterns. It can also speed up the process by automating the time-consuming elements of data linkage. Finally, machine learning can improve the scalability of data linkage by allowing organizations to process large volumes of data more efficiently.
If you’re interested in using machine learning to improve your data linkage process, there are a few things to keep in mind.
- First, you’ll need to have a good understanding of your data types and sources.
- Second, you’ll need to choose the right machine learning algorithm for your data and your goals.
- And third, you’ll need to tune your machine learning model to get the best results.
With the right approach, machine learning can help you overcome the inflexibility of data linkage and improve the overall quality of your data.
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up?
RecordLinker is here to help! Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


