Data Normalization Tools and Techniques: A Practical Guide

Szymon Zak
January 24, 2025

If you’ve ever taken a careful view at your organization’s data management habits, you’ve probably realized that there’s a lot of duplicate, messy data floating around, much of it logged in different formats.
Using poor quality data to inform insights and decision-making is at best inefficient; at worst dangerous, because you risk being misled. As you collect greater amounts of data, it can become increasingly difficult to see the forest through the trees.
Data normalization is meant to help organizations improve the accuracy, accessibility, and completeness of their data. At the most basic level, it includes a range of operations for cleansing, (re)structuring, and enriching data.
Core Data Normalization Techniques
Modern data normalization combines multiple techniques to handle complex data challenges.
String matching algorithms catch basic variations in spelling and formatting.
Advanced pattern recognition identifies relationships between seemingly different records.
Then there are also Machine Learning models that adapt to organization-specific naming conventions and data patterns.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Data integration software can also help you move data from one system to another. For example, you might use it to migrate data from an on-premises database to the cloud.
Whatever tools you are using your processes must support key normalization tasks:
- standardizing text formats and spellings
- matching variant forms of the same entity
- deduplicating records across systems
- understanding relationships
- maintaining consistent hierarchies
- validating data against business rules
The Manual Reality of Data Normalization
Following a manual process to normalize your data may be achievable if your organization is small and collects only a few types of data, but most organizations find this process extremely tedious and error-prone.
Data teams face a brutal truth when manual data matching consumes their days. Analysts and conversion specialists click through endless screens, maintain robust spreadsheets, version Excels, and juggle variations of company names across systems.
In insurance, a simple task like matching “Philadelphia Indemnity Insurance Co” to “PIIC” multiplies into dozens of manual decisions across various projects. It’s not hard in itself as a data normalization challenge, but these are heavily business-context-driven decisions.
Insurance brokers face this challenge daily. When integrating Agency Management Systems of acquired agencies, teams manually map thousands of carrier names and bound policies. Even if they have a modest degree of support from their core system vendors.
This manual effort consumes resources while introducing errors and delays.
Simple tools and manual work alone may be sufficient if your organization only stores data in one type of system. But what if you have data spread out across multiple departments, stored in different applications, and governed by completely different management practices – or maybe not governed at all? What if you are dealing with heavy M&A activity and post-merger system consolidation projects?
Regardless of tools, data normalization is still hard work in the trenches of data.
Something you cannot readily automate.
But there are more advanced tools supporting these tasks, right?

Traditional Tool Limitations
Current normalization tools take various approaches, each with significant drawbacks.
String Matching Tools focus on basic pattern recognition. They catch obvious variations like “Corp” versus “Corporation” but miss contextual relationships. They generate false matches while missing valid variations, forcing constant manual review.
Master Data Management Platforms try to become authoritative sources of standardized records. They create rigid hierarchies that clash with operational realities. Implementation drags on for months while business users resist adoption. By the way, a centralized MDM is the fastest way to shorten a CIO’s tenure.
ETL Solutions – extract, transform, and load – these tools extract data from source systems, transform it, and then typically load it into a central repository, such as a data warehouse or data mart. They work for one-off migrations but fail to maintain consistency as systems evolve. They solve temporary symptoms while ignoring root causes, typically ignoring data quality at the edges of your IT ecosystem.
Data Quality and Management Tools form a critical but often misunderstood layer in the normalization landscape. They promise clean, standardized data through rule-based cleansing, pattern matching, and validation checks. Yet these tools struggle with the living nature of enterprise data.
A bank of validation rules might catch basic data quality issues – malformed email addresses or invalid phone numbers. But they miss the deeper complexity of how organizations use and maintain their reference data. No static ruleset can anticipate how, for example, a merger will affect company hierarchies or how new market entrants should map to existing categories.
Neither using Excel for data standardization nor deterministic matching methods can solve normalization problems at sufficient scale. Then even vendor portals enabling data transformation/conversion between systems are a miss – no one develops core business systems with data admin roles in mind.
Why Classic Tech-First Approaches Fail
The way the tools are employed (or designed) comes with a misunderstanding how organizations actually use and maintain data. They assume perfect standardization – or even centralization – is both possible and desirable. Reality proves way messier.
Individual core business systems need flexibility to support specific processes. What looks like duplicate data often serves valid operational purposes. Forcing artificial uniformity between systems of different types disrupts essential workflows.
Data evolves constantly. New companies enter markets. Companies merge, rename, and change addresses. Static normalization rules and rigid tools can quickly become outdated.
New data gets constantly created at the edge in your end-systems.
Business users prioritize efficiency over perfection. They enter data in ways that make sense for their daily work. Tools that ignore this reality face resistance and increasingly crazier workarounds. Instead, data normalization solutions should be able to make sense of data – or at least make enough sense to enable better human decisions.
The Cost of Failed Normalization
Yet subpar handling of data normalization and quality creates real business impact.
Reporting accuracy suffers. Analysts spend more time cleaning data than analyzing it. Decision makers lose confidence in their information.
Operational efficiency drops. Users struggle to find correct records. Simple tasks require complex lookups and cross-references.
Data conversion projects extend months beyond schedule. Teams waste time manually mapping records between systems. Critical business initiatives stall while waiting for clean data.
The Real Gap in Data Normalization
Data normalization needs knowledgeable users, period. To handle it well you need people who know your:
- operational needs
- systems and data
- business
- industry
This expertise and hard work often remains unseen. Data admins, business systems analysts, data conversion specialists aren’t the first ones for accolades. We tend to call them the “silent teams” for a reason. If you are curious, here’s a guest podcast appearance about how crucial those roles are for larger insurance brokers.
The Unseen Data Heroes of Insurance – Listen to Our Guest Episode
Our founder, Roman Stepanenko, shares insights into challenges of data administrators and data conversion teams in insurance.
Discover the gaps in the process, and the reality of manual workflows of insurance's data people. They are some of the most hard-working and unnoticed 'silent teams'.
Data conversion analysts, business systems analysts, implementation specialists, and data admins keep large brokers going after agency acquisitions.
Why do those people matter so much?
Pure normalization focuses on technical cleanliness over business value. It assumes that perfect standardization delivers better results. Reality proves more complex. Here is what may happen if you take standardization too far or opt for rigid methods.
Business context gets lost through stripping away purposeful variations. Different departments need different views of the same data.
Integration complexity grows as each normalized system requires intricate mapping logic. Simple data loads become engineering projects.
There is no way you can get humans out of the equation. Ever.
The gap lies in usability and overwhelmingly underserved workflows of data teams.
You don’t need ultimate magic tech, or centralization – disruptive in the negative sense.
So, what should you be looking for in solutions that help data normalization in the optimal way?
Practical Requirements for Normalization Tools
Successful data normalization demands more than technical features. It requires tools that understand how organizations actually manage their data.
Before choosing a software package, review what you already have, and consider various elements of data management.
Core Normalization Features and Integration Capabilities
Modern tools must integrate deeply with existing systems. Bi-directional API connections enable real-time synchronization while ensuring system authority gets respected. But integration goes beyond connectivity – tools must understand industry-specific data models and business rules.
Solutions also need to be made for real end-users, and help them organize their work organically.
What does it give us? Aim for:
- light, bi-directional API integration with core business systems
- bulk processing and validation features
- intuitive interfaces for data administrators
- support for industry-specific matching rules
- change management and approval workflows
- collaboration and project management features
- Machine Learning, enabling decisions of your data experts
Technical Architecture Decisions
Cloud or on-premise? Cloud solutions offer flexibility and faster setup but raise data sovereignty questions. On-premise deployment provides control but increases maintenance overhead.
Data domain support means that tools must handle your specific data types – from structured database records to unstructured documents. They need sophisticated transformation capabilities for joining, filtering, and aggregating data across sources. Your software should be able to support the type(s) of data you work with. Some data normalization software is designed for specific data types, while other programs have a broader scope.
Do not overlook planning for scalability. Today’s small deployment can grow rapidly. Tools must scale to handle increasing data volumes, new data types, and additional source systems.
The software should be able to handle the types of transformations you need to perform on your data. Some common transformations include:
- joining data from multiple sources
- separating data by domain
- splitting data into multiple files
- filtering data based on certain criteria
- sorting data
- aggregating data
Do you need real-time access to updated data, or would near-real-time or batch updates be sufficient? Most basic data normalization software tends to process new data in batches. If you need up-to-the moment information (for example, on financial data) you may need to invest in a higher-end program.
Security and Compliance
Data normalization tools handle some of your organization’s most sensitive information – from customer records to business hierarchies. Security can’t be an afterthought or mere checkbox exercise. Modern tools must bake protection into every layer while enabling, not hindering, efficient data operations.
- encryption for data in transit and at rest
- access controls and audit logging
- data masking and anonymization features
- compliance with industry regulations
At minimum, your data normalization software should encrypt data while in transit and at rest.
Vendor Evaluation Criteria
Selecting normalization tools means choosing long-term technology partners. Features matter, but vendor stability and support shape daily operational reality. Technical capabilities mean little without responsive support teams and clear product evolution. Smart organizations evaluate vendors through both technical and partnership lenses.
- responsive support
- track record of timely feature development
- product roadmap aligned with your needs
- sustainable pricing model
- availability and active partnership post-purchase
Do you have the in-house expertise needed to manage the software? What kind of support does the company provide? Can they address your feature requests without putting them into a backlog for the unforeseeable future?
Try getting in touch with representatives before purchasing the software to gauge how responsive and helpful they are. They shouldn’t be hiding limitations and areas where work for initial setup or your specific use cases may be required. Remember that issues with your data normalization software could have significant consequences, so you need to be able to trust the company.
User-Oriented ML in Data Normalization: Meet RecordLinker
Are you acquiring businesses, migrating operations, or consolidating business systems? Do you have a system that suffers from duplication in entities due to persistent data migrations or data entry volume?
RecordLinker helps data teams with data standardization, quality reporting, mapping records, and ongoing data administration.
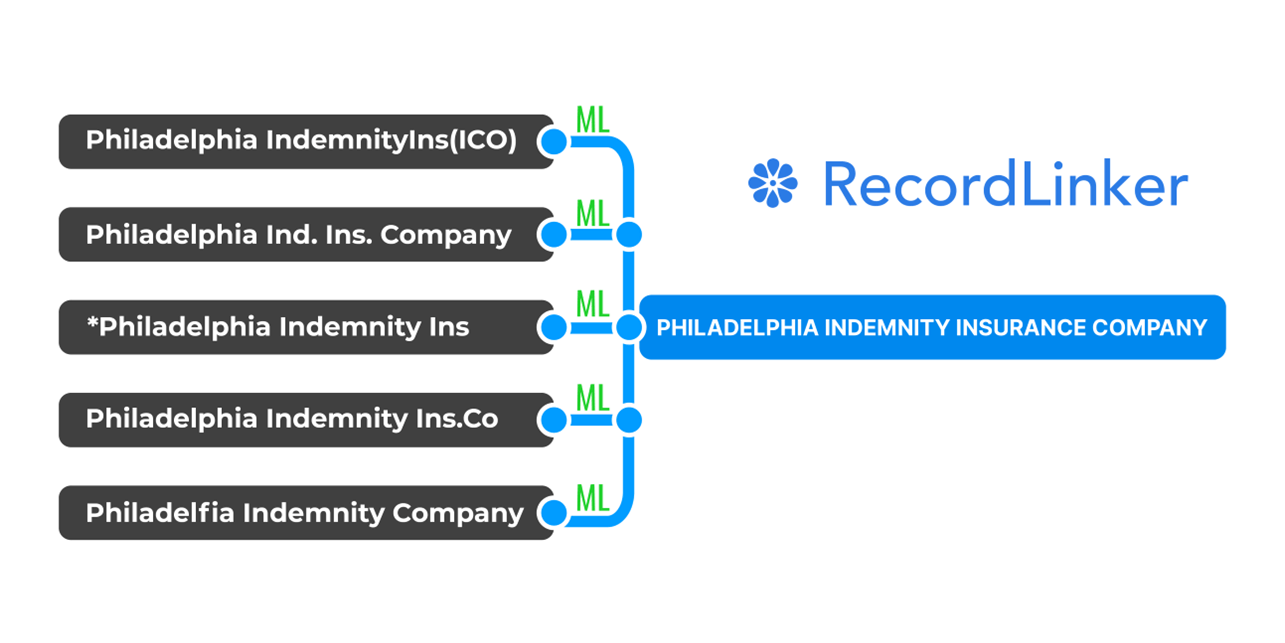
We could say that Machine Learning made us – but it’s the icing on the cake.
RecordLinker uses Machine Learning to match different spelling variations (often really wild spelling variants). It’s an excuse to provide end-user usability, enable team collaboration, and enhance human decisions.
Our system matches records based on confidence thresholds, suggests other possible matches, and makes sense of data. All that is oriented at one goal – helping your data team do their work.
RecordLinker can become a lever for throughput in your data normalization efforts. It will bring tremendous quality of life, and let your data experts (re)organize their workflow.
Even more so if your processes are particularly messy (think about versioning Excels with company codes and names, frantically using VLOOKUP and XLOOKUP, or having to repeatedly click 10 times through your system’s menus to do anything productive with data.
We are not an off-shelf product. To really help you, we need to understand your data model, the flavor of your problem, goals, and opportunities for integration to preconfigure our system. Only then we can deliver exceptional value.
Please, feel free to contact us for a demo. We provide a no-cost trial, allowing your data team to see that meaningful, positive change is finally possible.
Suggested Reading about Data Normalization
Take a look at our recommended reading list for practical and easy-to-understand resources. We cover topics in-depth to help you gain greater understanding of all things related to entity resolution, data quality, and standardization.
- [Guide] Advice for Building Your Own Entity Resolution Software
- Normalizing Names of Vendors, Suppliers, and Companies
- Machine Learning in Overcoming Record Linkage Inflexibility
- Large-Scale Data Mapping Tools and Techniques
- Automating Data Standardization with ML
- [Guide] Data Conversion Explained
- Data Integrity During Ongoing Data Management and Migrations


