Canonical Model in Data Architecture: Definition, Benefits, Principles
Roman Stepanenko
December 25, 2023

As our world grows increasingly reliant on big data, it’s more important than ever to have a system in place to manage it effectively. One key component of effective data management is the use of canonical models.
What Is Canonicalization in Data Management?
Canonicalization in reference to data simply means a process of standardizing data to a single format. To say that data is canonical, means that it is standardized (or normalized). Data stored in multiple sources can describe the same entities, while representing them in a non-uniform way. Canonicalization relies on converting or translating data variations to understand them as a universal set.
What Is a Canonical Model in Data Architecture?
A canonical model is a design pattern and a central approach to data architecture relying on a separate standard set of data used to represent every entity present across different systems. It creates a common platform for various systems to access data in a standardized format, and communicate.
Essentially, canonical data model serves as an intermediary between different systems that:
- acts as a mediator in data exchange between systems,
- handles data transformation and translation.
- creates a common format of data – rather than relying on communication between these systems on a point-to-point basis.
- facilitates data integration.
- enables data governance from data quality management, lineage tracking and auditing to compliance.
- promotes reusability and data consistency throughout data architecture (only if designed the right way).
- provides a single source of truth for reliable unsiloed use throughout the organization.
Operations in a canonical model don’t change input data itself, but rather they model and translate data coming from multiple points to create a separate superset.
This could be something as simple as a list of employee contact information or more complex sets of financial records, product information with attributes, customer profiles, or inventory data.

The benefits of using canonical models are many and varied. Perhaps most importantly, they provide a consistent way to view and work with data, which is essential for avoiding errors, maintaining accuracy and consistency, as well as maximizing profitability!
How Does a Canonical Model Work?
Canonical models are typically designed using a formal modeling language, such as the Unified Modeling Language (UML), which is a way of representing objects and relationships as a tree of data.
Once the canonical model has been designed, it can be implemented using software that supports the UML standard. RecordLinker, for instance, lets you create, associate records, and maintain canonical models – it’s built using a tree structure that’s similar to UML.
What Compontents Make a Canonical Data Model?
Let’s talk about principles in common data models in detail. You know the general definition – but let’s break down technical capabilities further.
1. Standardizing Data Formats
The principle of standardization is central to any canonical model. Data formats, spanning from simple lists to intricate relational structures, must adhere to a uniform schema to ensure interoperability and flexible integration. Your data model needs to be able to process data regardless of the input format.
Consider the example of an employee contact list scattered across various systems, each using distinct formats such as Excel, CSV, XML, or Google Sheets. The canonical data model for this scenario defines a consistent representation, perhaps specifying fields like first name, last name, email address, and phone number in a predefined order.
By establishing a common format independent of specific applications or systems, the canonical model facilitates smooth data exchange and communication, overcoming the limitations of disparate formats.
2. Standardizing Naming Conventions
Another use for canonical models is standardizing naming conventions between records. This is important because it can make it difficult to aggregate and perform operations on data when the naming conventions aren’t consistent. Divergent naming conventions across systems can create a domino effect, hindering data aggregation, analysis, trend discovery, and decision-making processes.
For instance, within an organization, different departments may refer to the same entity using varied terms or aliases (e.g., “Microsoft” vs. “Microsoft_Corp”). Without standardized naming conventions, searching for and consolidating relevant data becomes a cumbersome task, impeding operational efficiency and resulting with fragmented data.
There’s no guarantee that a data analyst, administrator, or engineer would remember to do this consistently. Top that with thousands of records, and dealing with disparate records becomes unmaintainable.
By establishing a unified taxonomy and nomenclature, the canonical model ensures coherence and clarity in data representation, simplifying data retrieval and enhancing organizational agility. This is especially important when dealing with large amounts of data, or when aggregating data from multiple sources.
3. Data Transformation and Mapping
In the reality of enterprise-scale data integration, harmonizing disparate data sources is a big challenge. Canonical data models excel in this domain by facilitating data transformation and mapping.
Data originating from diverse sources, each with its unique schema and semantics, undergo transformation within the canonical model to align with the standardized format. This process involves mapping data attributes, reconciling differences, and resolving conflicts to create a unified view of the information landscape.
Through data transformation and mapping, the canonical data model acts as a bridge between wildly different data environments, enabling efficient integration and interoperability.
4. Metadata Management
Metadata (data describing data) is the invisible matrix that helps understanding, organizing, and managing the information ecosystem. Within a canonical data model, comprehensive metadata management is essential for ensuring data quality, lineage, and governance.
Metadata artifacts, including data definitions, lineage information, and usage policies, provide insights into the structure, semantics, and provenance of the data. By putting in place and maintaining metadata repositories, organizations can enhance data governance, open development to more flexiblity, and facilitate compliance with regulatory requiremente..
5. Version Control and Governance
Effective governance mechanisms are indispensable for maintaining the integrity and relevance of a canonical data model. Version control ensures that changes to the data model are tracked, documented, and managed systematically, preventing inadvertent modifications and ensuring data lineage integrity.
Governance processes, encompassing access controls, data stewardship, and compliance policies, establish rules and guidelines for managing the data model lifecycle. Through version control and governance, organizations can uphold data quality standards, mitigate risks, and foster a culture of accountability and transparency in data management practices.
6. Integration with Master Data Management (MDM)
Mentioning the integration of canonical data models with master data management (MDM) systems could provide a broader perspective on data management practices. MDM systems help organizations manage and synchronize master data entities, such as customers, products, and suppliers, across different systems and applications.
Canonical data models often serve as the foundation for MDM initiatives, providing a consistent representation of master records.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Benefits of Using Canonical Models
59% of companies use analytics in some capacity. Canonical models help you maximize the value of those analytics, and squeeze every last drop of value out of your data.
There are many benefits to using canonical models, including:
1. Limited Translations, Less Dependancies, Maintainable Business Logic
The more systems and the more they are interconnected on a point-to-point basis, the greater advantage provided by a CDM. This is a large technical benefit from the perspective of data architecture and integration.
- With a CDM for 5 systems you get 5 separate, two-way connections, which result in the maximum of 10 translations while 5 systems connected point-to-point can result with up to 20 translations.
- When a system gets upgraded to a new version or gets replaced by a new one, all you need to do is to replace translations between CDM and that system. If that system was on its own connected with 4 different systems, you’d have to prepare translation pairs for each of them.
- When it comes to business logic for communication between systems, it should be contained in the CDM. Without a common model point-to-point connections rely on logic in separate systems that contain pieces of data models from systems they are connected with. With a point-to-point integration, this also requires a rework when a change occurs in data formats or systems you use.
2. Improved Data Quality
By providing a single source of truth against different naming conventions, canonical models can help to improve the overall quality of your data. They ensure consistency and accuracy across your data.
In addition, the use of canonical models can help to ensure that data is consistently formatted and structured (especially if it’s coming from different systems), which can make it easier to import into different platforms and work with.
3. Increased Efficiency
Working with multiple copies of the same data can be time-consuming and inefficient. Canonical models can help to reduce the amount of time spent on data entry and maintenance, as well as identifying and handling duplicate records.
When data is consistently formatted and structured, it enables automation of processes, which can lead to further efficiency gains.
Having a canonical data model in place will likely reduce time of delivery of your reports while also making analytics less fragmented and more likely to uncover trends.
4. Reduced Costs
The increased efficiency offered by canonical models can lead to direct cost savings, such as reduced storage costs, IT development, and reduced administrative labor costs with data maintenance.
Plus, when it comes time to buy or sell assets, whether data-assets or otherwise, having a well-defined and structured canonical model can help to increase the value of those assets.
5. Improved Compliance
In addition, canonical models can make it easier to comply with data-related regulations, such as the General Data Protection Regulation (GDPR).
This is because they can help to ensure that only accurate and up-to-date data is stored, which decreases the gross number of entries (through deduplication and removal of incorrect records) and helps meet GDPR requirements.
CDM may by design help you holistically help you apply mandatory industry standards for data exchange between systems. This reduces the overhead in compliance and may protect you from legal issues.

6. Interoperability
In today’s interconnected world, seamless integration between different systems and applications is essential.
CDMs act as the glue that binds disparate data sources together, enabling smooth communication and collaboration across departments and technologies. This interoperability streamlines processes, enhances productivity, and unlocks new opportunities for innovation.
7. Scalability
As your business grows and evolves, so does your data. CDMs provide a scalable framework that can adapt to changing needs and requirements.
Adapting to the evolving needs of your business, CDMs are a part of data infrastructure that works as a foundation for data integration. Whether entering new markets, launching products, or acquiring companies, Common data model ensures your data infrastructure remains agile, ready, and responsive.
Canonical Data Models: Design Principles and Advice
Planning and definining – you need to know what you have to know. Here are some questions to help you navigate through the initial design stage.
- Why do you need your common data model?
- What systems are involved?
- Where do they store data?
- What structure and formats do they use?
- What realtions do you expect?
- What metadata and schemas do you need?
Simplicity – Keep it simple! Complexity breeds confusion, so strive for clarity and elegance in your CDM design. Focus on capturing the essential elements without unnecessary embellishment or complication.
- Ultimately, your canonical model should be free of business logic and dependancies between sets of individual systems. Wrap as much as you can into your CDM to make it maintainable.
- Having 3 or more interconnected systems that makes you suffer as soon as you change one of them (you’d have to rewrite logic in 3 systems to establish dependancies).
- CDM offers you a possibility to have business logic just between CDM and individual systems, which limits the number of translations and enables you to move less painfully with system integration, occasional changes in data formats, or switching individual systems.
Flexibility – change is inevitable, especially in today’s fast-paced business environment.
- Design your CDMs to be adaptable, with capabilities for accommodating new requirements and evolving use cases.
- Central approach is not always beneficial, and overlaps and dependancies in use cases between between departments and teams may vary.
- Some teams could be given more autonomy in specifying their parts. Allow some decentralized organization of blocks in your data model. (more on that below).
Compartmentalization – this is a very important guideline to keep in mind, while it is entailed by flexibility, it deserves full attention.
- It’s more feasable to organize your common data model piece by piece rather than making a uniform model that tries to describe everything.
- UML standard slammed on a big static repository may not be useful and user-friendly, even if it seemingly benefits the top decision makers, shortens development (not always), or feels as a good approach when you think only about how few systems you have today.
- Instead, you may think about collecting data models across your organization, and creating a “model of models” tied in an index with elastic search.
Collaboration – building a CDM is a team effort that requires input from various stakeholders, including business users, data architects, and IT professionals as well as consideration for operational needs.
- Foster open communication and collaboration to ensure that everyone’s needs and perspectives are taken into account.
- While your CDM is meant to inform the upper levles of your organizaion, it will be used intensively by many teams at the front of various proesses.
- Listen to end-users, learn their usage contexts and needs.
- While your CDM helps in centralizing your data, becoming less siloed, and attaining a holistic business view – for operational purposes and efficient adoption, you do need to think in a decentralized way during planning and implementation.
- Otherwise you risk creating something that teams hate to deal with and refuse to recognize as an improvement.
Standardization – consistency is key to effective data management.
- When designing CDMs, adhere to industry standards and best practices.
- Consider applying machine learning for linking your records, and automating work, especially when your systems collect new data on a regular basis.
- Consider employing a mechanism for updating or checking changes in canonical records (e.g. companies can merge, change names, and receive industry ratings). This is not always possible in your systems, but you could still bring that to your CDM as a way of enriching data or improving quality-of-life of and operational efficiency in your teams.
Documentation – document, document, document!
- Comprehensive documentation is essential for understanding, maintaining, and evolving CDMs over time.
- Capture key decisions, definitions, and dependencies to provide a roadmap for future reference and refinement.

More Reading About MDM and Data in Business
A canonical data model is only a small piece of data management practices that help you achieve consistency in data and drive your business. Here’s what you need to know about data management and data use in business:
- 3 Core MDM Principles For Every Business
- Data Matching in Excel: The Way To Stay Slow
- [Guide] Building Your Own Record Linkage Solution with ML
- Customer Data Integration Throught Record Linkage
- KPIs Analytics: Making Sense of Disparate Data Sources
- Master Data Management Implementation: Best Practices
- Optimizing Your ERP’s Master Data For Better Performance
Final Thoughts About Canonical Models
Canonical data models serve as the guiding stars in your data architecture by providing clarity, consistency, and cohesion to crucial information in your organization. By embracing CDMs and adhering to their principles of design, businesses can unlock a world of benefits, from improved decision-making and operational efficiency to enhanced collaboration and innovation.
Canonical models are a key component of effective data management. With companies increasingly relying on data to drive their business decisions, the use of canonical models is likely to become more widespread.
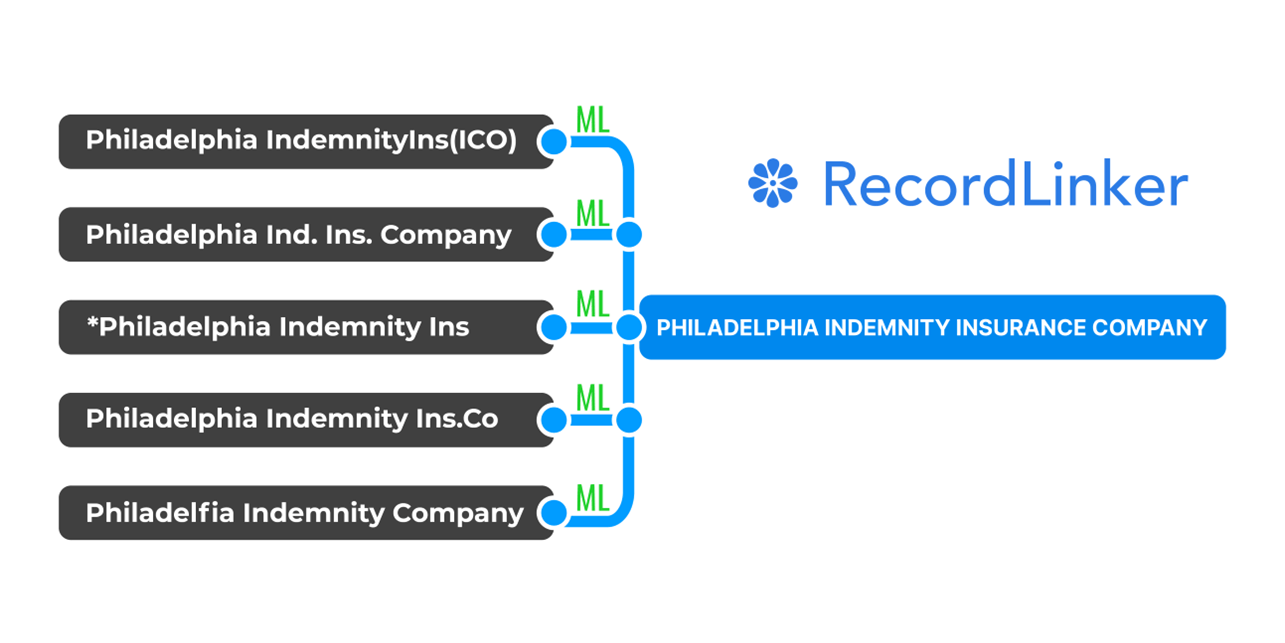
RecordLinker uses Machine Learning to normalize records across your data systems!
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up? RecordLinker is here to help. Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


