Comparing and Matching Data in Excel: Why It Fails
Roman Stepanenko
March 5, 2024

In today’s organizational landscape, data-driven decision-making is vital, but collecting that data is only half the battle. Your company might be logging scores of records on customers, products, or suppliers, but if you can’t organize and make sense of data, you may be doing more harm than good.
You should be able to trust that your most important data is complete, accurate, up-to-date, and accessible to those who need it. Otherwise, you risk wasting resources constantly trying to patch it all up–or, worse, making important decisions based on wrong or fragmented information.
In 2022, many companies still struggle to manage and use their data. One of the most common challenges they face is data messiness. Individuals or teams may log data on the same “entity” (person, place, or thing) in entirely different ways.
Data Entry, Real World, and Disparate Records
Many companies still rely on manual data entry, often without proper data governance. Multiple disparate systems, various people handling data entry as well as different practices by department, company branch, vendors, suppliers, and third party administrators – all that contributes to creating sets of data that vary greatly.
For example, a client named Billy-Bob McGraw might be logged as “BB McGraw” by the customer support team and “Billy-Bob MacGraw” by the accounting team. Within each team, naming conventions, misspellings and other errors may create even more surprising variations.
If you wanted to link all your company’s records concerning Billy-Bob, you’d have a problem. The usual methods and tools for finding and matching records would be stymied by inconsistencies in spelling. Even a small typo in an entry, like an extra space, could complicate the process.
How Data Matching Works In Excel
Excel and other types of spreadsheets rely on formulas. It’s not just that specific formulas work in a very defined way like VLOOKUP. The foundations behind formulas are often very rigid, because spreadsheets are first and foremost meant for calculations.
The problem with real world data like names, locations, addresses, and company names is that these types of data are very unstructured.
Many organizations look to Microsoft Excel to solve their record linking issues. But as powerful and well-crafted a program as Excel is, it is not designed as a record linkage tool, and trying to turn it into one will almost certainly lead to frustration down the road.
How Excel is Used for Comparing and Matching Data
Organizations that use Excel for record linkage base their approach around the concept of canonical values (or golden records). In other words, they will choose standardized (“canonical”) formats for how each entity should appear in their datasets.
For example, a business might decide that Billy Bob McGraw should always be logged as “McGraw, BB”. Or, depending on their data management goals, they may choose to fit specific items into a larger category. An insurance company may decide that “fire” and “flood” should both appear as “property risk” in their policy databases.
They will then design a central Excel sheet where data from around the company can be imported and converted to match the canonical value.
Usually, these sheets have two columns. Column A shows the imported data entries, and column B matches each entry with its canonical value.
Importing the data for column A is simple, but populating the canonical values in column B presents a host of challenges.

Coping with Excel Data Linkage
Most organizations use Excel’s Data Validation function to populate column B, creating drop-downs of canonical values to ensure they are formatted correctly for each entry. This is just slightly better than fully manual matching of entries, because it adds a layer of consistency.
When you first set up the drop-down, the manual work involved in keeping it up to date may seem manageable, and it probably would continue to be so if it weren’t for the fact that data, especially when it relates to people, is highly changeable. Naturally, this is by no means scalable and creates a large work overhead, especially in organizations that are fed new records daily.
Excel is not very good at handling data that is constantly changing. It is designed to be a static, unchanging program. If you want to change a value in a cell, you have to do it manually. There is no way to automate the process.
Yes, for updating existing values you may use the find and replace feature, but it implies that you know exactly what needs to be changed. While you can use wildcard operators, they get less and less useful the lengthier the values, or the more complex the data, inviting unintentional changes, and leaving behind anything that doesn’t match operators in your string.
Formulas are a partial, but still an imperfect answer. They may work for data cleaned enough to feel somewhat structured. They work well with numbers, but not so much with text records that may have multiple variations, including misspellings, shortened words, and shifts in word order.
Data Validation Through Enormous Drop-Downs
Putting your canonical values in a drop-down list, rather than writing them all into column B manually, helps ensure that they are used consistently. But as your company and data collection capabilities grow, so will your list of canonical values. In fact, it’s not unheard of for companies to have canonical value drop-downs containing hundreds, or even thousands of items!
Even a drop-down with dozens of entries is much too long. Scrolling down to find the right canonical value for each item in column A would be extremely tedious. It likely won’t take long for the size of your drop-down to start severely impacting the user-friendliness of the Excel file, leading to wasted time and frustrated employees.
Even if your company is relatively small, you probably don’t want to feel limited in the number of canonical values you can use. If, for any reason, you decide to take a more granular approach to data management, or add new types of data to the mix, your Excel file shouldn’t hold you back.
Labor-intensity of Drop-Downs
The drop-down list will not only grow; it will also change. Someone will need to be responsible for adding, updating, renaming, and merging canonical values.
At first, this will probably constitute a small additional duty for one employee. But as the list grows, maintaining it will eat up a progressively larger chunk of that person’s workday.
You will probably need to rename, merge, or otherwise change canonical values on a fairly frequent, ad hoc basis.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Excel Formulas for Matching and Comparing Data
Formulas! Why not use IF statements or VLOOKUP? They are very rigid as a deterministic method of matching data, which again, works well with structured, clean, small and relatviely simple sets of data.
They are inflexible when it comes to misspellings, shifts in word order, and abbreviated text or realy heavily on supporting columns with dictionaries of variants you only have thought of or already discovered.
IF statements may get lengthy and hard to maintain when you are dealing with a large data set. They also suffer when you are dealing with data that’s changing, forcing you to expand and fix them. This is neither scalable nor maintainable in the long run.
What about VLOOKUP with an approximate match? Honestly, it’s bad – even with relatively simple types of data like names and surnames, it leads to mismatched linkages.
Another problem with VLOOKUP is that it looks for the first value it can find. This becomes a big problem when there are multiple records in the input data that need linking.
Fuzzy Lookup Add-In from Microsoft Research
There is an add-in provided by Microsoft called Fuzzy Lookup that assesses and tries to match values based on similarity scoring. So finally you get something of a probabilistic way of linking records!
Unfortunately, it has its limits. The more complex the data type and the wilder the naming differences you are dealing with, the less likely it is to provide reliable matches.
If your data set contains many seemingly similar entries that belong to different golden records, the more confusing fuzzy lookup gets up to a point fuzzy lookup falls short of useless. It may handle person names fairly well, but not necessarily a long list of insurance company names or a mountain of product variants from a specialized and granular manufacturing category.
On top of everything, fuzzy lookup is nothing like a fully-fledged machine learning matching algorithm that can get retrained to improve with time. Machine learning in record linkage tasks can achieve as much as 95% matched records. Proper ML algorithms beat Excel-based ways of data matching by orders of magnitude.
Versions and Collaboration in Data Matching Work
Finally, consider the communication challenges this process will generate. Each time the list is updated, a new version of the sheet must be shared.
The potential for miscommunication here is huge. For example, imagine that a developer receives a copy of the file via email and begins transferring the data. Midway through this process, the creator of the file reaches out to explain that there were some errors in that version, and he has just created a new one.
The developer will have to start the entire data process over from the beginning, since figuring out which individual items were changed would simply take too much time.
Missing emails or allowing old file versions to float around your intranet can seriously undermine a number of business processes. It’s much harder to prevent these types of human errors than it is to implement a more streamlined record linkage process from the beginning.

Data Matching (Record Linkage) Is Not Just About Matching
Here’s something we at RecordLinker know as people behind a record linkage solution. There are multiple things to consider when developing a tool for professionals with a designated task like data conversion and core system data migrations.
It’s more than just giving someone any technical ability of linking records. Spreadsheets aren’t user friendly, they don’t use UI to help data teams organize their work. Raw rows and columns aren’t great when it comes to showing relationships and hierarchy e.g. between parent and child companies.
Excel doesn’t really provide collaboration options, approvals, and other business or quality-of-life needs clients and end-users have.
Check our features to fully understand how much more there is than just linking data.
Data matching isn’t just a task, it’s a business process that can get streamlined with various additions. Modern UI and helpful features change a lot – by introducing focus, consistency, and quality-of-life upgrades for people who standardize data on a regular basis. This is one of the reasons why you may want to consider a record linkage tool, other than automation and efficiency.
Master Data Management: The Holistic Approach To Data
Is your organization still moving Excels around? Repeatedly trying to join data from disparate systems?
It could be the right moment to look into Master Data Management – a strategy, a set of processes, rules, and elements of automation for keeping your data accurate, organized, and available to people in your organization. Putting MDM in place will most likely remediate many issues resulting from manual entry, cleaning, and handling data from disparate systems.
Master Data Management enables long-term scalability and builds a foundation for efficient data processess, covering: integration, cleansing, harmonization, security, and governance.
Start with these 3 articles:
- 5 Key Areas in Master Data Management
- Benefits of MDM Software
- Master Data Management Implementation: Best Practices
Automate Record Linkage the Right Way
Excel is an excellent program for many business processes, but it’s simply the wrong tool for record linkage. It’s a spreadsheet program, not a database. That means it has a number of inherent limitations that make it poorly suited for the task of maintaining a canonical list of values.
So, with Excel off the table, how should you tackle the challenge of linking messy data? Your best bet is to create or adopt a record linkage solution like RecordLinker that is dedicated to this task. A machine learning-powered platform can automatically link records to canonical values, becoming more accurate and capable of handling nuance over time.
Not only will this allow you to automate many of the more tedious aspects of data management; it will grow with your business, so you avoid the headache and expense of having to revise your data entry processes down the road.
RecordLinker uses Machine Learning to normalize records across your data systems!
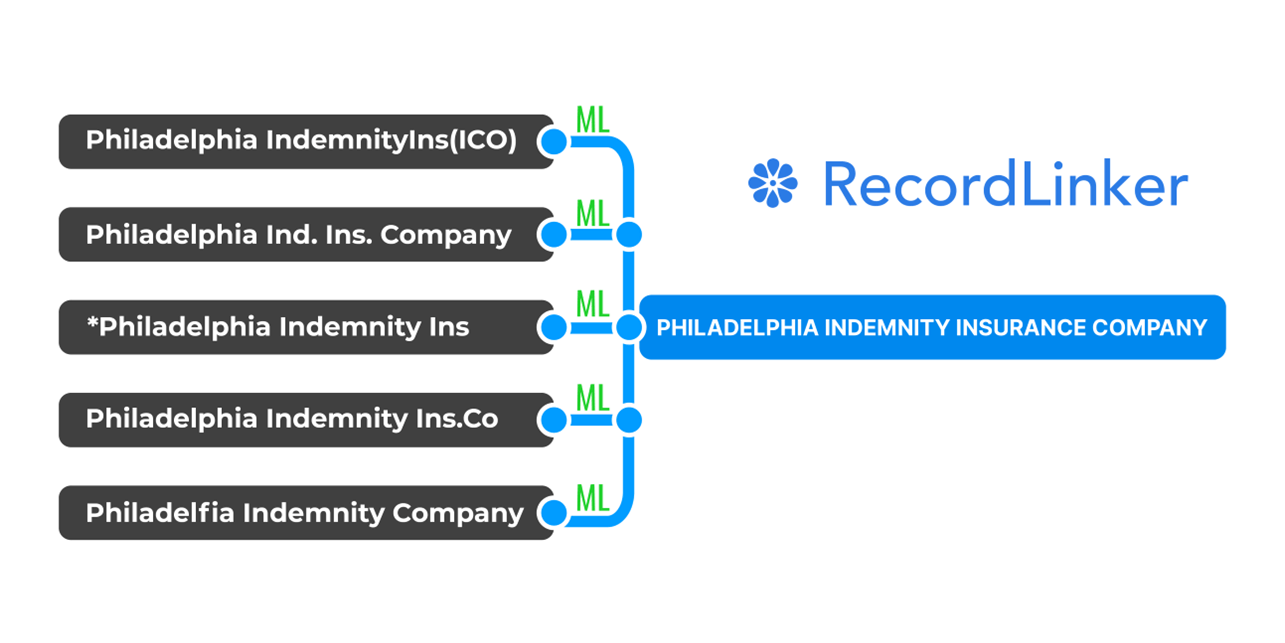
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up? RecordLinker is here to help. Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


