Big Data in Business Analytics vs. Entity Resolution
Roman Stepanenko
February 14, 2024
The term “heterogeneous data” refers to a body of data that comprises multiple formats and sources. For example, customer data may be scattered across various databases, CRM systems, and spreadsheets.
With so many sources involved, it can be difficult to get a complete and accurate picture. In enteprise settings and companies relying heavily on data, various data sets grow at a pace that requires scalable approach to collecting, integrating, maintaining, and processing to turn them into something reliably useful to enable accurate and holistic business analytics.

What Exactly Is Big Data?
Big Data is about complexity and exponentiality of its growth. Datasets containing big data are beyond capability of regular data management and manual maintenance to upkeep, process, and analyze them. Big data can encompass structured, partly structured, and unstructured data all mixed together. The main characteristic of big data that it grows at a staggering pace.
Big data can emcompass many categories, including user profiles and behavioral attributes, service usage data, supply chain management, product lifecycle indicators, electronic health records, etc. It can include many, many entries in your databases that are described by various attributes, with many attributes that hold a lot of insights.
Big Data and Disparities in Business Analytics
Your records may be coming from different systems. In their raw form they may be just pieces of information adding more and more attributes to what’s of interest to you – like users, customers, usage data.
The problem is these pieces of information are not necessarily linked, therefore often unready for reliable business analysis.
While you can offset some of disparities between records by designing your online analytics and data collection to avoid fragmented data, this is not always possible.
Often systems rely on manual data entry, sometimes you are not in control of external systems of your vendors, suppliers, third party administrators etc. Not every business is purely online at its core (unlike big companies running apps). This exposes it to collecting a lot of unstructured or partly structured data – and real world data is usually unstructured.
What Makes an Entity in Data?
So, an entity is a collection of records that describe to the same thing. A useful entity in your database is the product of relationships established between records. You may have a data table that describes an entity and several supplementary tables.
What Entity Resolution Means to Business Analytics?
Entity resolution is a process of identifying and matching data across different sources, so that it can be consolidated and analyzed as a single body of data. It’s a process that takes multiple objects describing the same thing and links them together, so it creates a complete picture. This means that all records of a particular “entity” (a person, place or thing) must be identified, disambiguated, and linked.
For instance, a customer is a single entity. But records pertaining to customers may be messy. Names may be misspelled in one database, and addresses might be listed in different formats across various databases.
Entity resolution is a critical part of data management, but it can be a challenge, particularly with Big Data. Fortunately, there are a few general guidelines that will help you approach entity resolution the right way.
How to Deal with Big Data in Business Analytics
Dealing with big data in business analytics requires a systematic approach that focuses on data infrastructure, quality, and fostering a data-driven culture.
Businesses need robust data infrastructure capable of handling large volumes of data efficiently. This includes scalable storage solutions and distributed computing frameworks.
Prioritizing data quality and governance ensures the accuracy and reliability of data assets. Implementing data validation, cleansing, and enrichment techniques improves data quality and trustworthiness.
Leveraging advanced analytics techniques, such as machine learning and predictive modeling, helps extract actionable insights from big data. Data visualization tools facilitate effective communication of insights.
Fostering a culture of data-driven decision-making involves promoting data literacy and analytical skills among employees. Providing training and resources empowers employees to interpret and analyze data effectively.
Here’s what to do to achieve succcess in dealing with business analytics in big data.
1. Understand Your Data
Invest time in mapping out the types of data you have, how it is structured, and what patterns exist within it. This may sound like a no-brainer, but data is too often collected without any clear understanding of what it represents or how it will be used.
What kinds of entities are present within your data, and what are their attributes and relationships? Laying this out will provide you with a roadmap for how to approach entity resolution.
2. Identify Your Match Criteria
Once you have a good understanding of your data, you need to identify what criteria you will use to match entities. This can be tricky, as there is no single “correct” way to match entities.
Different organizations will create match criteria based on their specific needs and goals. However, there are some general best practices that can be followed.
Firstly, use unique identifiers whenever possible. Attributes that are entirely unique to a particular entity (e.g., social security numbers, email addresses, etc.) are the best means of linking records. If you have unique identifiers for your entities, use them!
If you cannot rely on unique identifiers, you will need to use multiple attributes to match entities. The more attributes you can use, the more likely you are to find an accurate match.
When in doubt, err on the side of simplicity. Complex matching rules are more likely to produce false positives (records that are incorrectly linked) and false negatives (records that are incorrectly not linked).
Once you’ve determined which fields to match on, you’ll need to decide how lenient or strict you want your matches to be. For example, you may want to match customer records that have the same last name, even if the first name is different.
Or, you may want to match records that have the same address, even if the street name is spelled differently.
The more flexible your match criteria, the more likely you are to find matches. But be careful not to be too lenient, or you may end up with a lot of false positives.
3. Cleanse Your Data

Before you start matching records, it’s important to consider the quality of your data. Data quality issues can lead to both false positives and false negatives, which can impact the accuracy of your entity resolution.
To ensure high-quality matches, you should check your data for common quality issues like missing values, incorrect values, and duplicates. You can fix these issues manually, or with the help of an efficient automated data cleansing tool.
4. Start Matching Your Records
After you have defined your match criteria and cleaned up your data, it’s time to start linking records. Depending on the complexity of your data, you may choose to do this manually. But in the Big Data age, many organizations are turning to automated tools.
You may even decide to create an in-house entity resolution tool on your own. We’ve written a guide covering aspects of approaching this
Manual matching is an option with small data sets, or those with a limited number of match fields. To manually match records, you’ll need to compare each record side-by-side and determine whether or not they meet your match criteria. As you might expect, this can be an extremely time-consuming process.
Automated tools can greatly speed up the entity resolution process and improve its accuracy. These tools can help to identify and match data across different sources, as well as clean and consolidate the data.
5. Introduce Machine Learning to Entity Resolution
Depending on what you want to link, machine learning can allow you to establish a flexible record linkage pipeline. Deterministic, strict rules may be enough just cover obvious resolvable records – but they will get lost with records that vary a lot, suffer from abbreviations, shifts in word order etc.
You may be working with many records that are really similar while they describe vastly different entities. This also creates a barrier for rigid rules and convetional matching algorithms.
The answer to that is machine learning, a probabilistic approach of matching data that makes use of confidence scores. ML-based record linkage solution is likely to be scalable and able to grow with your organization thanks to its ability to retrain itself with consecutive linkage completions.
It can still leave you in control of what and how gets liked with approval and editing options (at least this is the approach we took with RecordLinker).
It’s generally a good idea to test your process on a few small data sets before going live. This will help you fine-tune your matching rules, find edge cases, and get a feel for the process before tackling a larger amount of data.

Build Your Business Analytics
After you are done linking data and confirm that you are left with complete, accurately described entities it’s time to turn to analytics and data visualization solutions.
You need to be careful though and consider the scale of both data you want to process and the scope of your analysis. In their basic tiers, out-of-the-box tools may have fairly low processing limits and usage tokens.
Check these two articles to find tips about BI and reporting: KPIs Analytics in Business: Integrating Data from Multiple Sources as well as Benefits of Superior Data Linking for Customer Data Integration.
Big Data in Business Analytics Wrapped Up
Big Data is like gold in today’s business landscape, but collecting it is just the first step. Without measures in place to ensure the quality and manageability of those large data sets, you may end up making poor decisions, wasting time and money, and losing customer trust.
That means entity resolution is more important than ever. By approaching it in an organized, thoughtful way, you can quickly turn messy, disparate data sets into a powerful foundation for growth.
More Reading About Business Analytics and Scalable Data Management
By no means regaining control over your data is something you can achieve overnight.
It requires knowledge, planning, and careful design to ensure you end up with something that’s helpful and widely embraced by your organization. Here are several selected texts to help you prepare and review different areas of interest:
- Master Data Management: Key Implementation Benefits
- MDM Implementation Best Practices to Follow
- Comparing and Matching Data in Excel – The Wrong Tool for Record Linkage
- Name Normalization: Matching Company Names for Partners, Suppliers, Vendors
- Using Machine Learning to Improve Your Data in MDM
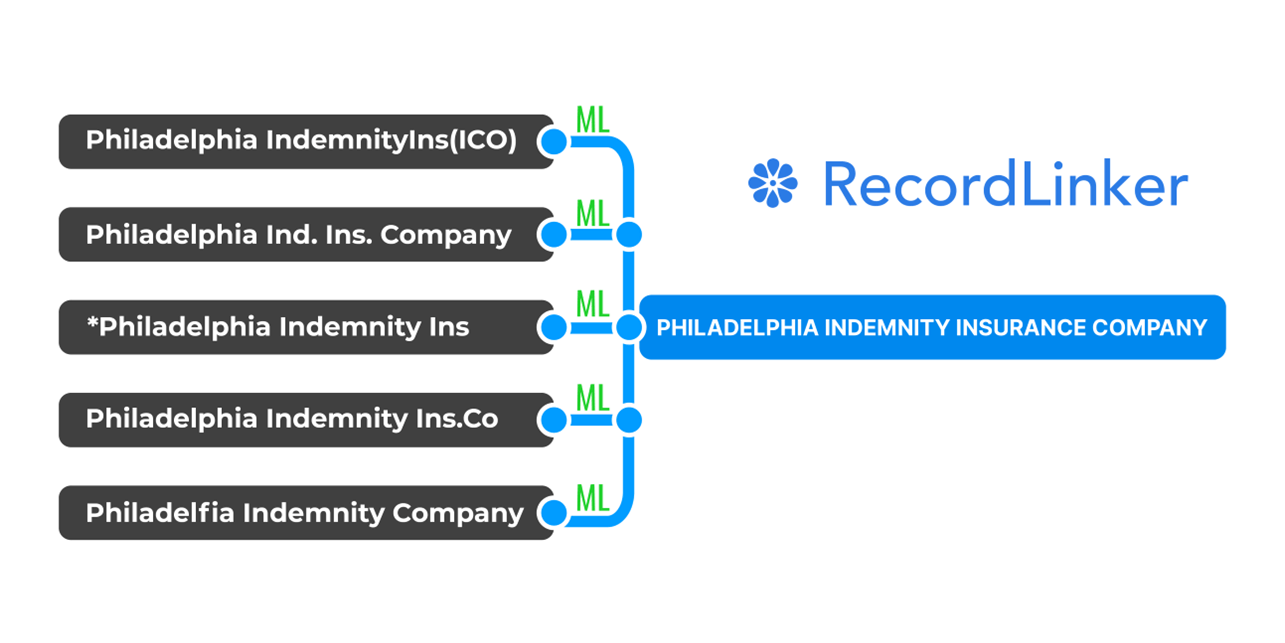
RecordLinker uses Machine Learning to normalize records across your data systems!
Interested in improving the quality of your data, but don’t have the time or resources to create a master data management program from the ground-up? RecordLinker is here to help. Our data integration and management platform can quickly connect your disparate data sources, identify and deduplicate records, and keep your data clean and up-to-date.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


