Data Warehouse Design: Naming Standards
Roman Stepanenko
December 15, 2023
For businesses, to make sense of the exponentially growing data, formatting and standardizing it in a consistent way becomes crucial. You can’t achieve holistic, consistent analytics when a data warehouse or data mart doesn’t serve its purpose with data siting there unstandardized, unlinked, and fragmented.

Consider a hypothetical scenario: your company is in the midst of buyout negotiations with a larger corporation. As part of the proceedings, your organization needs to disclose its Salesforce revenues, its vendors, and other financial information.
Here, poor standardization practices play against you. If your organization uses different spellings for the same vendor across different departments or datasets – say, ‘Microsoft’ vs. ‘Microsoft_Corporation’ – it becomes significantly more difficult for the other party to understand exactly who you’re doing business with and what value you bring to their operations.
Your stated vendors or profits might look significantly different than they really are, which in turn could lead to the other corporation lowballing their offer, or worse – walking away from the deal entirely, having skewed or incomplete understanding of your business.
The challenges don’t end there. Even if your vendor data appears standardized – missing or incomplete data in your business intelligence (BI) reports can further complicate matters. Imagine having to admit that certain pieces of financial data were omitted from your reports due to issues with the design of your data warehouse’s objects. Presenting incomplete data or present multiple fragmented reports with convoluted explainations of how reporting works take aways the strength of your arguments.
In such a scenario, your analysts may have had to resort to complex data stitching techniques, involving transformations, workarounds like supporting linkage tables, and filters in the BI layer, just to make sense of the available data. This complexity not only raises doubts about the accuracy and reliability of your data but also risks undermining the trustworthiness of your organization in the eyes of the other party’s due diligence team. If it happens that you had to resort to patchwork BI fixes, there’s a chance there are mistakes you could be oblivious to – and the last thing you want is to someone from the outside uncover them.
Ensuring data consistency and completeness of your organization’s data infrastructure is paramount, especially in high-stakes situations like buyout negotiations. By addressing these challenges and implementing robust data management practices, organizations can build confidence around their data integrity.

Dangers of Wonky Data Warehouse Design
Let’s delve into more issues, because a poorly maintained data warehouse data-quality-wise can come into the way of your business daily. You can’t use a piece of your data infrastructure typically meant to be a single source of truth when it doesn’t work as one!
1. Inaccurate Reporting
Without standardization, data from different sources while describing specific real-world entities (e.g. products, branches, vendors, policies, clients) will be hard to link, and most often end up representing fragmented separate pieces and duplicates, which may lead to confusion in reporting.
Unstandardized names and disparate pieces of data hinder the ability to perform meaningful analytics and derive actionable insights. Analysts may struggle to aggregate and reconcile data from different sources, even if technically it is already stored in a shared environment, limiting their ability to uncover valuable patterns, trends, and correlations.
This domino effect goes fruther to impair decision-making.
2. Limited Data Accessibility
In a data warehouse with unlinked and fragmented data, users may encounter difficulties accessing the information they need. This can lead to inefficiencies in data retrieval and analysis, slowing down decision-making processes and impeding operational agility.
People handling data administration and reporting may want to look up specfiic records. When naming standards in data warehouses aren’t in place, this increases the likelyhood that certain pieces of data aren’t linked, or vary in spelling and word order so much, that they will likely get left out from user queries.
3. Challenges in Data Governance
Lack of standardized naming conventions and fragmented data pose significant challenges to data governance initiatives. It becomes difficult to enforce data policies, maintain data lineage, and ensure compliance with regulatory requirements, leading to increased risks and potential regulatory violations.
If there’s nothing in place that ensures data quality and naming standards, then all there is left to do is either to ignore it in the short run, or take a futile attempt at enforcing these rules by designated employees.
Benefits of Naming Standards in Data Warehouses
Data quality and naming standards aren’t just a gimmick to make things look neat for the sake of the art. Tidied up, standardized, and linked records as well as properly described tables and columns help people efficiently do their work and collaborate with a shared understanding of business!
1. Accuracy and Completeness
Inaccurate and incomplete data is one of the biggest problems facing data-dependent businesses today. Standardizing record names can help ensure that your data is both accurate and complete.
For example, let’s say you have a vendor CRM with thousands of records. If your CRM is like many other large, archaic CRMs, mostly made up of manually entered data, it’s probably full of duplicates, typos, and other errors. This can make it difficult to get an accurate picture of your vendor base.
Data standardization can help to clean up your database and make it more accurate. By implementing rules such as “vendor names must be entered in all caps” or “postal codes must be entered in the XXXX-XXXX format,” you can ensure that your data is entered in a consistent way, making it much easier to manage down the line.
2. Facilitated Data Integration and Interoperability
Consistent naming conventions promote seamless integration of data mart with other systems and data sources within the organization. When data elements are uniformly labeled and structured, it becomes easier to map and align them during the integration process, minimizing errors and ensuring data interoperability.
Standardized names enable you to link specific records with confidence to establish a complete representation of entities scattered throughout multiple data sources.
This also ensures there is less work outside the data warehouse in tools that are meant to draw from it. Great input data for your analytical soolutions limits the need to transform data, create filtering rules, and conditional logic to bring everything to order inside BI software.
Your analysts will spend less time trying to fix data and creating super specific workarounds on their side. Leaving data transformation within the data mart is the optimal way, because think what happens when one end your BI team grows a set of transformations and filters, and then it stops working – possibly causing issues – because someone changed or finally fixed data either in the source system or in your data warehouse.
3. Improved Data Usability
Now, let’s think about actual objects that structure your data mart. A consistent naming convention for tables, columns, and other data mart objects ensures uniformity and clarity across the data environment. Proper naming practices let users easily understand the purpose and content of each data element, facilitating data interpretation and analysis. The user-experience of navigating through everything becomes way more consistent.
A well-defined naming convention enables data discovery and access for users, reducing the time and effort required to locate relevant data. With reliable and intuitive naming, users can quickly identify the datasets they need and navigate the data mart more efficiently, improving overall usability and productivity.
4. Simplified Maintenance, Governance, and Scalability
Data warehouses and data mart are often built preciesly with handling exponentially growing data sets in mind. A standardized naming convention simplifies data mart maintenance and management tasks, particularly as the data volume, scope, and environment evolves.
With a clear and consistent structure in place, administrators can more easily identify and manage data assets, streamline updates and modifications, and scale the data mart infrastructure to accommodate changing business needs.
When you introduce and automatically enforce rules for name standardization and validation, your data governance team’s focus shifts from manual maintenance and discovery to monitoring, addressing reported problems, and working on new initiatives. Less time goes towards finding out whether there are any issues in the first place.
5. Collaboration and Communication
A standardized naming convention fosters better collaboration and communication among data stakeholders, including analysts, developers, and business users.
With a common language and understanding of data elements, teams can more effectively communicate requirements, establish and analyze KPIs across different data sources, share insights, and collaborate on data-related projects, driving innovation and alignment across the organization.

Understanding Data Warehouse Naming Standards
Data warehouse naming standards ensure consistency, clarity, and manageability within your data environment. These standards establish guidelines for naming various components of your data warehouse, including both the structural elements that organize your data mart and the individual data records and attributes contained within it.
There are two levels to which naming standards and conventions apply:
- Structural elements – objects that make and organize your data mart.
- Data naming – actual data, individual records with their attributes.
Structural Naming Standards
At the structural level, naming standards apply to the objects that comprise your data mart. These objects include tables, views, indexes, and other database entities responsible for organizing and storing your data. Adhering to consistent naming conventions for these objects enhances data organization and accessibility. Examples of structural naming standards include:
- Table Names: Tables should be named descriptively to reflect their contents or purpose. For example, a table storing customer information could be named “customer_data” or “customer_info.”
- View Names: Views provide virtual representations of data from one or more tables. Clear and meaningful names help users understand the data presented by the view. For instance, a view aggregating sales data could be named “sales_summary_view.”
- Index Names: Indexes improve query performance by facilitating faster data retrieval. Naming conventions for indexes should indicate the columns they index and their purpose. For example, an index on the “customer_id” column could be named “ix_customer_id.”
Data Naming Standards
Beyond the structural components, naming standards also apply to the data itself — the individual records and attributes stored within the data warehouse. Consistent naming conventions for data elements promote understanding, consistency, and interoperability across different datasets. Examples of data naming standards include:
- Column Names: Columns represent specific attributes or characteristics of the data stored in a table. Descriptive column names should convey the meaning or content of the data they contain. For example, a column storing customer names could be named “customer_name” or “customer_full_name.”
- Attribute Names: Attributes define the properties or characteristics of a data record. Standardized attribute names ensure uniformity and clarity across different datasets. For instance, attributes representing date values could be named “order_date” or “transaction_date.”
By introducing and adhering to comprehensive naming standards at both the structural and data levels, organizations can streamline data management processes, improve data quality, and enhance the usability and accessibility of their data warehouse.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Standards and Coherence in Your Data Warehouse
Know what you are working with! Depending on what makes your data warehouse, the preferred standards may be different! Certain solutions may offer support for specific conventions while other won’t. It could be case sensitivty, word separation symbols etc.
Establishing Structural Naming Standards
To create structural naming standards for your data warehouse, follow these actionable tips while considering the variability in preferred standards and platform support:
- Assess Platform Compatibility – understand the capabilities and limitations of your data warehouse platform in terms of naming conventions. Different solutions may offer varying levels of support for specific conventions, such as case sensitivity and word separation symbols. Ensure that your chosen conventions align with the capabilities of your platform.
- Snowflake defaults to storing all objects in uppercase, while BigQuery is case insensitive and defaults to lowercase object names. Then you have SQL keywords that are typically in uppercase. Remember that, opting for lowercase names for your data objects can enhance readability for human readers – humans read words partly by shapes, and uppercase letters create a rectangular pattern that takes this factor away.
- Containing information about versions, ownership, and partitions is a debatable issue. It adds technical utility, but often end-users don’t care. Make sure tables and columns are descriptive from a human perspective. Only then think about anything extra.
- Microsoft solutions allow column names with spaces, a feature also supported by Snowflake. However, BigQuery and Amazon Redshift do not support spaces in column names.
- Similarly, while most Enterprise Data Warehouses (EDWs) support hyphens, they need to be enclosed by added characters. To enhance query descriptiveness and readability, it’s preferable to use underscores as separators.
- Define Flexible Naming Conventions – establish naming conventions that accommodate the platform requirements while promoting consistency and clarity. Consider factors like readability and application to business use cases, While flexibility and space for accomodating attributes, prefixes, and suffixes is welcome, you shouldn’t stray from the core of your naming convention. Anyone should be able to reliably make use of names of objects and data attributes.
- Be descriptive and add context – there’s nothing worse than leaving someone wondering what a specific attribute is about. “City” could refer to anything, it would be helpful to inform end-users by adding specificty to data they are working with. Having a way to distinguish between the city of birth, the city of where the service was provided, or their residence could be relevant.
- Document Platform-Specific Considerations – document any platform-specific considerations or constraints related to naming standards. Identify features or functionalities that may impact naming conventions, such as limitations on character length or special characters. By documenting these considerations, you can ensure alignment between naming standards and platform capabilities. This ensures your BI speicalists find exactly what they need and stay productive.
- Enforce Consistency – implement mechanisms to enforce naming consistency. Utilize MDM automation elements or custom scripts to validate and standardize naming practices, taking into account the unique requirements of each platform.
Establishing Data Naming Standards
To create data naming standards for your data warehouse, consider the following actionable tips while accounting for platform-specific variations:
- Understand Platform-Specific Preferences – assess platform-specific preferences and conventions regarding data naming. Different platforms may have distinct preferences for naming attributes, columns, and other data elements. Familiarize yourself with platform-specific guidelines to ensure interoperability, and your end-users.
- Adapt Naming Guidelines – develop naming guidelines that can be adapted to accommodate platform-specific preferences while maintaining consistency and coherence. Again, consider factors like platform capabilities, data modeling requirements, industry standards, and user experience when defining naming conventions.
- Validate Compatibility – validate the compatibility of naming standards with the features and functionalities of your data warehouse platform. Ensure that naming conventions adhere to platform-specific constraints, such as character limitations or reserved keywords. Check compatibility through testing and validation processes to prevent data integrity issues and ensure seamless data operations.
- Provide Platform-Specific Training and Support – offer platform-specific training and support to data stakeholders to ensure effective adoption of naming standards. Provide guidance on how to apply naming conventions within the context of the chosen data warehouse platform, including best practices and troubleshooting tips. Platform-specific training enhances user proficiency and promotes consistency in data naming practices across the organization.

The Importance of Record Linkage in Data Warehousing
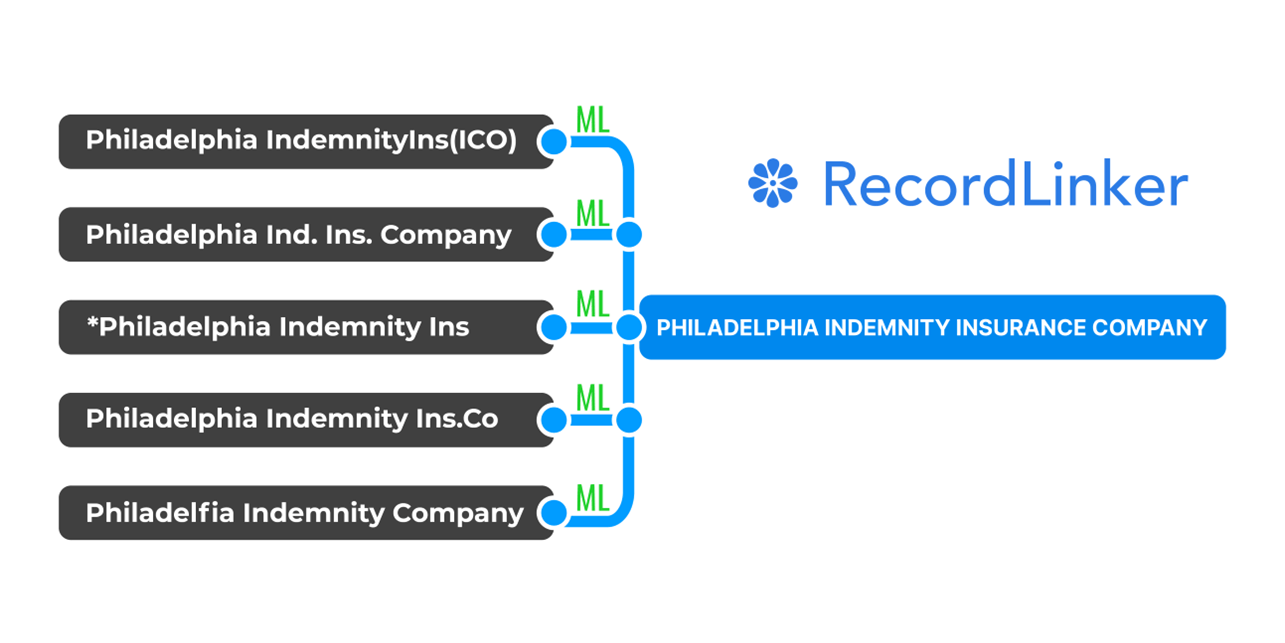
Record linkage plays a pivotal role in data warehousing, particularly in ensuring data accuracy and completeness to prevent fragmented reporting and cost overruns. Record linkage is making sure that individual records are pointing to a single entity they describe, which lets you to analyze items of business interest as a whole like customer, vendor, supplier profiles, product data etc.
Check these if you want to find more specifics about data linkage or think about solution options:
- Types of Record Linkage Solutions
- [Guide] Developing an ML Record Linkage Tool
- RecordLinker’s list of features
Here let’s look at examples where unlinked pieces of data describing specific entitties may come into the way of your business.
Imagine a retail company relying on its data warehouse to analyze customer purchasing behavior and preferences. Inaccurate or incomplete customer data, such as duplicate records or inconsistent information, can result in flawed insights and ineffective decision-making.
For instance, if the data warehouse contains multiple entries for the same customer under different variations of their name or contact details, the company may mistakenly attribute multiple purchases to different individuals, leading to skewed analysis and calculations of metrics like Customer Lifetime Value. By leveraging record linkage techniques to accurately link related customer records across disparate datasets, the company can ensure a single, comprehensive view of each customer, enabling more accurate analysis and targeted marketing efforts.
Similarly, consider a financial institution using its data warehouse to assess credit risk and make lending decisions. Inaccurate or incomplete borrower information, such as inconsistent income data or missing employment history, can compromise the accuracy of credit assessments and increase the risk of default. By applying record linkage algorithms to match and consolidate relevant borrower information from multiple sources, including credit reports, loan applications, and financial statements, the institution can enhance the accuracy of its risk assessments and make more informed lending decisions, ultimately reducing the likelihood of financial losses due to defaults.
Moreover, in the healthcare industry, a hospital’s data warehouse serves as a central repository for patient medical records and treatment history. Inaccurate or incomplete patient data, such as duplicate entries or missing diagnoses, can jeopardize patient care and compromise clinical decision-making. For example, if a patient’s medical history is scattered across multiple records with inconsistent identifiers, healthcare providers may struggle to access critical information during emergencies or treatment planning, potentially leading to adverse outcomes. By implementing record linkage algorithms to identify and reconcile duplicate or fragmented patient records, the hospital can ensure the integrity and accessibility of patient data, improving the quality of care and patient outcomes.
In each of these examples, record linkage plays a crucial role in maintaining data integrity, enabling accurate analysis and decision-making, and ultimately driving business success. By investing in robust record linkage processes, organizations can unlock the full potential of their data assets and gain a competitive edge, becoming truly data-driven.
Learn More About Name Standardization and Data Management
Congratulations! You want to master you data for the benefit of your organization. Business needs, use cases, scope, broader data management, surrounding tools and practices – it’s a rabbit hole of knowledge and choices. Here’s more reading to help you plan and prepare for successfully building a data-driven organization.
- Using Your Data: KPIs Analytics vs. Multiple Data Sources
- Entity Resolution and Big Data in Business Analytics
- Benefits of Customer Data Integration
- Flexible Machine-Learning-Based Data Linkage
- Canonical Model in Data Architecture: Benefits and Design Principles
Final Thoughts: Standards and Consistency in Data Warehouses
Implementing effective naming standards and record linkage processes can significantly enhance the reliability and usability of your data warehouse. Here’s what you need to remember:
- Standardize Naming Conventions:
- Establish clear and consistent naming conventions for tables, columns, and data elements.
- Document these conventions to ensure alignment across stakeholders and data management processes.
- Automate Record Linkage:
- Utilize automated algorithms and data quality tools to streamline record linkage processes.
- Implement robust matching algorithms and validation mechanisms to ensure accurate identification of related records.
- Regularly Monitor Data Quality:
- Implement proactive data quality monitoring and validation processes to detect and address inconsistencies or errors.
- Conduct regular audits and assessments to maintain data integrity and reliability over time.
- Provide User Training and Support:
- Offer comprehensive training and support to data stakeholders on the importance of naming standards and record linkage practices.
- Provide platform-specific guidance and best practices to enhance proficiency and promote consistency in data management processes.
- Continuous Improvement and Adaptation:
- Foster a culture of continuous improvement by soliciting feedback from users and stakeholders.
- Adapt naming conventions and data management practices to align with evolving business needs and technological advancements.
RecordLinker uses Machine Learning to map records across data systems and standardize data marts!
Interested in improving the quality of your data mart? You don’t have time to develop proprietary tools? Rebuilding your architecture to include data standardization means large changes in your ETL?
RecordLinker is pluggable, and requires light integrations at best. Ask us for a demo to learn what we can do and let’s work on a POC that matches your business needs, our entity resolution platform is highly customizable and can be pre-configured in line with your use cases.
To learn more about how RecordLinker can help you improve the quality of your data, request a free demo!


