Name Normalization – Name Matching for Companies, Vendors, Suppliers, and More!

Szymon Zak
February 2, 2024

In a 2020 survey, 77% of American organizations indicated that they value data-driven decision-making.
But how reliable is all that data?
If you were to take stock of all the data your company is keeping on partners, suppliers, vendors, contractors, customers, and products, would you be confident that it’s all consistent? If not, then you’re far from alone!
Many companies struggle with maintaining consistent names in their systems. For example, you might notice a problem with different company names being used for the same supplier. A company logged as 'Biggles Engineering Solutions' in one department’s database might be 'Biggles & Co' in another.
Think about other shifts in word order, abbreviations, misspellings, and so on!
One of the extreme cases we have observed in the insurance industry was a company with over 800 unique case insensitive spellings in a data mart!
Large Problems Caused by Disparate Records
This isn’t just an occasional annoyance. Record matching failures directly impact core business functions:
- You can’t fully integrate your business with your acquisition’s target post-M&A
- Analytics deliver skewed insights when they can’t consolidate data into proper entities
- Customer experience suffers from fragmented views of relationship history
- Operational inefficiencies multiply with each additional system or data source
Inconsistent names for entities can also prevent you from gaining a holistic view of what’s going on in your company, causing you to miss connections, trends, opportunities, and threats. It leads to fragmentation in your reporting and forces BI teams to keep adding filters and reporting workarounds instead of working with actual data analysis to gain insights.
But rather than chasing after errors and trying to clean up data manually, there’s a way to automate the process – and keep things from getting messy again in the future.
Traditional Approaches to Company Name Matching
Most organizations initially attempt simple approaches to solve record matching
Data teams and admins usually try to go after the first available solution. Usually it’s spreadsheets – but Excel is the wrong tool for name normalization and data linkage. Data validation functions in Excel, VLOOKUP, XLOOKUP, fuzzy matching algorithms, RegEx rules – these are neither a maintanable nor scalable ways of fixing data in the long run.
In many cases Excel is used as a workflow and mapping interface, note-taking tool for inputs, payload and the final format ingestible by the destination system.
Excel can be hard to get rid of entirely from the process – but it frames human work in a harmful way that is not scalable.
Deterministic algorithms – rules-based approaches using exact matching, pattern recognition, or scoring systems. These methods break down when confronting real-world data variation.
Vendor-specific tools – system-provided utilities that help with matching but typically only work within their own ecosystem and still require significant manual effort.
The insurance industry illustrates this challenge vividly. When brokers acquire agencies, their data conversion teams must map carriers with names like 'Philadelphia Indemnity Insurance Company' to variants like 'Phil Ind Insurance' or 'PIIC' across different Agency Management Systems.
The problem is that formulas and standard ways of solving that through programming are deterministic approaches to name normalization. This way of dealing with disparate records is inflexible, because it usually requires closely matching variants to produce reliable results.
Real-world data is unstructured, and people get outstandingly creative with manual data entry.
Free Book: Practical Guide to Implementing Entity Resolution
Interested in implementing an in-house record matching solution with your own development team without using any outside vendors or tools?

Manual normalization of names may be enough if you are dealing with small data sets and a limited number of data sources. However, it quickly collapses in an enterprise-scale setting where hundreds if not thousands records come in daily.
The Operational Cost of Suboptimal Name Normalization
Using poor name matching methods and tools not made to support human work in this area, immediately translates into inefficiencies in the proces. These inefficiencies are hidden costs.
- Data migrations and data conversion projects can take 2-3x longer than planned.
- Expensive consultants brought in for system conversions.
- Data conversion teams
work nights and weekendsduring critical transitions undertight deadlinesandhuge stress. - Analysts waste their time on
field-by-field mappingandreconciling inconsistent data. - Every year you grow and the volume of record grows, you have to constantly expand your data team to compensate.
The most significant impact occurs during organizational growth and change. Mergers, acquisitions, and system consolidations amplify these problems as disparate data environments collide.
What can you do about all that?

Improve Data Quality and Normalize Names at Scale
First, let’s look at some tips on how to make your data quality better to begin with, how to ensure your data is better prepared for normalization. Then let’s look at modern, scalable solutions.
1. Identify Your Data Sources
Next, you’ll need to identify all the locations where important entities are being logged – the departments and teams where it lives, and the (possibly multiple) core business systems being used to host it.
This may take some digging, but it’s important to give yourself a full picture of where your data is coming from before you can hope to fix any inconsistencies.
2. Find Out Who Does The Job
Take time to meet your data admins, and understand why their job is hard. Many core business systems offer limited ability to manage data at large scale, let alone offer any help in cleanup and normalization.
If you are responsible for (data) operations and feel that your processes are dragging, there’s probably a reason for that, and it’s not your data people. As a matter of fact, they may already be working at their capacity when it comes to data migration projects and name normalization tasks.
The Unseen Data Heroes of Insurance – Listen to Our Guest Episode
Our founder, Roman Stepanenko, shares insights into challenges of data administrators and data conversion teams in insurance.
Discover the gaps in the process, and the reality of manual workflows of insurance's data people. They are some of the most hard-working and unnoticed 'silent teams'.
Data conversion analysts, business systems analysts, implementation specialists, and data admins keep large brokers going after agency acquisitions.
3. Understand Why Your Vendor’s Data Interfaces Don’t Help
The very short answer is that modules for data mapping and data management are a feature made for a few people in your company. Your system’s vendor has no incentive to invest in them.
That’s why the entire process is either twisted around Excel-heavy work or vintage data conversion portals with mile-long dropdowns that lack even as little as filtering and search. Often, to edit a single entity in your system or to remap related entities elsewhere, you data people need to endlessly click through multiple screens in various places of your core business system.
4. Review and Cleanse Data in Your Destination System(s)
Going back to your problem with different company names being used across databases, it’s decision time. You’ll need to track down the inconsistencies and decide which is the correct name for this and all other “entities” (people, places, all defined objects being logged).
Only once you’ve decided on the correct names for your entities, you can standardize them. This means creating a consistent format for how the data is entered. For example, you might want to use all uppercase letters for company names. Establishing proper data governance practices is vital for improving and maintaining quality of your data.
Now, you’ll need to embark on a process to fix all data entries that deviate from your new standardized formats, as well as fill in any missing information and correct other types of inaccuracies.
If you have a limited number of data sources, you may be able to get away with manual data entry and cleanup. But if you have numerous sources across a variety of systems, you’ll likely want to purchase or develop a data linkage software solution that can quickly and easily bring your data into line.
5. Create Sustainable Data Practices
Of course, a one-time cleanse of your data isn’t enough. You’ll need to take steps to ensure your new standards are upheld going forward.
Single data cleanup projects deliver temporary benefits. Without structural changes, entity variations will reappear as your business grows.
Establish ongoing data quality processes rather than one-time projects. This includes intake validation, periodic quality reviews, and clear accountability for data stewardship. Document your standards in straightforward language that balances consistency with practical implementation.
The challenge isn’t creating standards — it’s making them work in real business environments where speed often trumps precision. The most effective approaches combine realistic standards with tools that make compliance easier than non-compliance.
Ultimately, you will also need a solution – but remember that it should also support humans.

Employing Machine Learning for Name Normalization Tasks
Remember the part about deterministic ways to link data? Machine learning presents a different approach, a probabilistic method of linking data.
Essentially, Machine Learning links records based on confidence scoring, while also being able train itself to be better and better based on name normalization tasks completed in the past. It’s flexible, smart, and can sustain your data normalization as your organization grows.
Excel and standard programming approaches based on rules can only somewhat add efficiency to name normalization. Often they leave you with a lot of mislinked records to fix, or are unable to handle cases in which a few records match a single entity. This is not an issue with Machine Learning.
The best part? Machine learning doesn’t have to take away your control over how data is linked. From our experience with RecordLinker, we took guided, semi-automated approach to linkages, which leaves your data admins with options to approve and edit linkages, or even create missing canonical records.
The Benefits of Machine Learning in Name Matching
Machine learning transforms record matching by learning from patterns rather than following rigid rules. This approach:
- Automatically identifies relationships between different naming conventions.
- Adapts to organization-specific patterns in your data.
- Improves accuracy over time through retraining.
- Handles even creative spelling variations, abbreviations, and non-standard affixes.
- Provides confidence scores to maintain human oversight where it is needed.
Unlike deterministic methods, ML can recognize that 'Phily Indem. Ins.' and 'Philadelphia Indemnity' likely refer to the same entity without relying on exact character matching.
The shift from deterministic to probabilistic matching represents a fundamental change in how organizations can approach data consolidation.
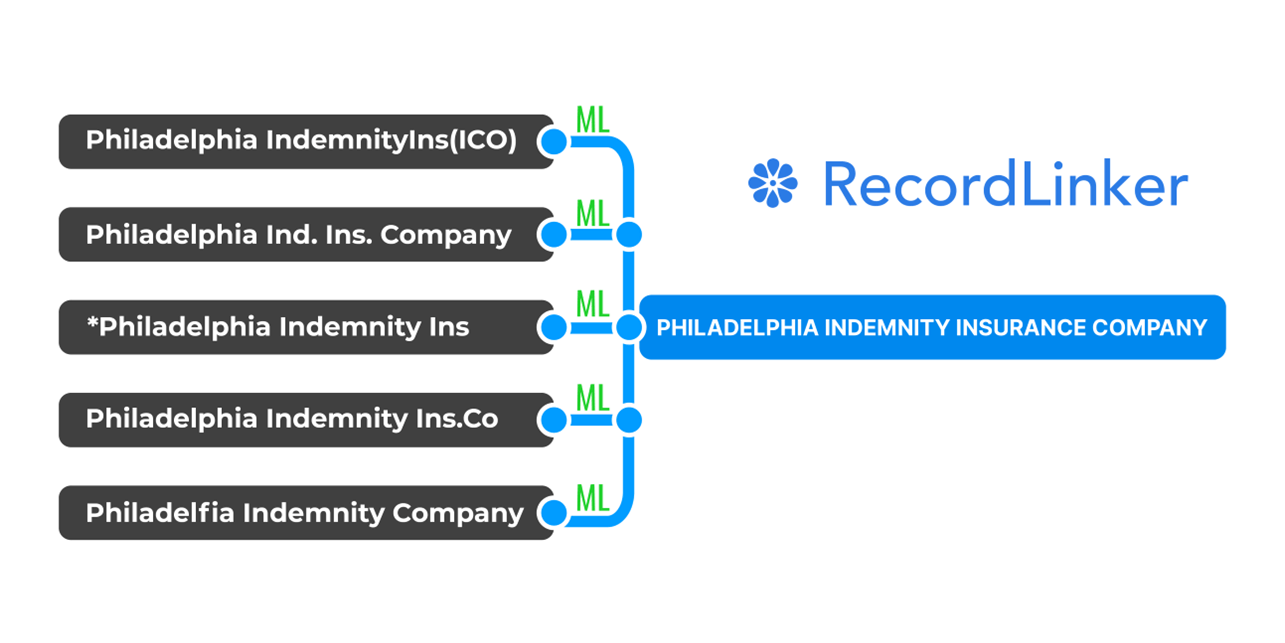
Implementing Better Name Normalization with ML
When evaluating name matching approaches, focus on Machine Learning solutions that:
- Easily integrate with your system – by connecting to your systems via bi-directional API or at least using standard report imports
- Respect system autonomy – your tool should enhance rather than replace your existing systems.
- Support human oversight – ML should not make final black-box decisions, because your data analysts need context, ability to edit and approve matches.
- Enable collaboration – the times when one person could handle mapping tasks are gone, migration teams, implementation teams etc. need to work together rather than side by side.
- Adapt to your context – Machine Learning should align with your specific naming patterns and conventions.
The most successful implementations start with specific use cases rather than attempting enterprise-wide transformation. Begin with a high-value scenario like consolidating company names or supporting a system migration and post-M&A data conversion.
The Real Secret to Success with Data Normalization Solutions
Data normalization technology fails when it ignores human workflows. Tools cannot just manipulate data points. Excel-based approaches persist not because they work well, but because nothing better fits how data teams actually function.
Technology is for nothing if it doesn’t support human decisions and (re)frame flawed business processes.
You can’t run your CRM in an Excel, why would you let it happen to a critical data function?
Data administrators need tools built for their actual tasks. Current workflows force skilled specialists to waste hours on mechanical data entry rather than applying their expertise. The right solution provides:
- Contextual interfaces that present relevant information without endless clicking. Data admins shouldn’t need to navigate five screens to complete a single mapping decision.
- Intelligent filtering that helps teams focus on priority records. When facing thousands of potential matches, admins need to tackle high-impact items first rather than drowning in an unsorted data ocean.
Business rule checks,validation, andguardrailsthat enforce proper output.- Work organization that enables project-based approaches. Teams need to segment work into manageable chunks rather than facing an endless, undifferentiated backlog.
- Ability to ingest your input and destination data as well as automatically generate ouput files in the format you need (which often gets done manually).
The real transformation happens when solutions provide superior workflow management, not just better algorithms. Teams need the ability to organize work around projects, track progress, document decisions, and maintain context between sessions.
Trust us, we’ve built RecordLinker – and we talked with dozens of client data teams. It’s uninimaginable how painful, wasteful, and convoluted workflows can be for the simplest data mapping or data management task. The end-users performing these tasks often haven’t seen a single meaningful change throughout their entire career.
Your data teams are knowledge-first, not data-entry-first.
They are dealing with a massive workflow gap above anything.

Meet RecordLinker: Friendly Normalization Workflow for Data Superheroes
RecordLinker transforms record matching from a technical problem into a practical workflow solution assisted with Machine Learning. It addresses the fundamental challenge data teams face: connecting different representations of the same entity across systems (or within a data mart) without endless manual labor.
Beyond Algorithms to Workflow
Most data normalization solutions focus solely on matching accuracy.
RecordLinker recognizes that the real problem lies in the broken processes surrounding data work.
It connects directly to core systems through bi-directional API integration or makes use of Excel imports, eliminating weeks of waiting for database backup restoration during migration projects. For insurance brokers, this means mapping carrier names into Applied Epic or migrating records into AMS360 can begin immediately after an agency acquisition deal.
Machine Learning with Human Context
RecordLinker’s approach combines ML with human judgment:
- The system identifies potential matches with confidence scores.
- It learns from your organization’s specific naming patterns.
- Machine suggestions grow more accurate from your completed projects.
- Human teams maintain final approval authority.
This balance respects that algorithms excel at pattern recognition while humans provide context and business knowledge.
Built for Real Data Teams
What sets RecordLinker apart is its understanding of how data teams actually work. The platform replaces spreadsheet chaos with structured workflows that support collaboration across specialists.
Teams can organize work into projects, focus on priority records through intelligent filtering, and maintain context without endless clicking through conversion portals.
The platform serves both immediate conversion needs and ongoing data management, recognizing that record normalization is both a project activity during transitions and a continuous requirement for data quality.
RecordLinker doesn’t try to be everything – it focuses on making record matching more efficient for the people who handle it daily. It transforms one of data management’s most tedious tasks into a structured, manageable process that recognizes data migration / conversion / admin teams as data-first experts rather than data entry clerks.

Large-Scale Normalization of Names Wrapped Up
The shift from rules-based matching to Machine Learning represents more than a technical upgrade. It addresses the core reality of business data: people will always create variations in how they reference the same entities. ML adapts to these patterns rather than fighting against them.
Effective implementations don’t just deploy algorithms — they reshape workflows. They connect to source systems without disrupting them, respect how teams actually work, and provide clear mechanisms for human judgment. The most successful organizations don’t attempt wholesale transformation. They target specific high-value use cases where better name matching delivers immediate operational benefits.
Name matching lacks the glamour of AI chatbots or predictive analytics, but it addresses a foundational challenge in data integration. Companies that solve this problem build the essential groundwork for reliable analytics and efficient operations. The goal is letting teams work confidently with the imperfect data that exists in every organization.
Don’t underestimate the importance of this seemingly mundane capability. Every downstream data initiative depends on knowing when different records refer to the same real-world entity. Get this right, and everything else in your data ecosystem becomes more powerful and trustworthy.
Recommended Reading About Data Matching and Data Management
Master data management and scalable naming normalization are complex topics. Approaching MDM is not just about implementing a bunch of solutions, rules, and automations. It requires a shift in the organization’s way of approaching data to succeed and turn it truly data-driven. Here are several articles to help you plan and put proper data management practices in place:
- Machine Learning in MDM for Improving Data Quality
- Building a Proprietary Data Linkage Tool For Name Matching
- Data Mapping Between Systems: Keys, Values, Relationships (with P&C Insurance Examples)
- Data Mapping Tools and Techniques for Enterprise Scale
- Machine Learning in Entity Resolution: Automating Data Standardization at Scale
- Data Conversion 101: Definition, Complementary Terms, Enterprise Uses
- Guidelines For Creating And Managing A Canonical Record Set


